Configuring Authorization
권한은 부여된 자원과 서비스를 대상으로 누가 접근하여 무엇을 통제할지에 대한 내용을 다룹니다. 특히 이전 개별적으로 존재하였던 IT 시스템과 달리 Hadoop은 기업 내의 모든 데이터를 저장하고 이를 기반으로 처리되는 Enterprise Data hub 역할을 담당하기 때문에, 좀더 다양하고 세분화된 권한 관리 제어 기능을 요구하고 있습니다. Hadoop 관리 도구들은 설정 및 유지보수를 다음과 같은 방식을 통해 간소화 할 수 있습니다:
- 모든 사용자들을 그룹화하며, 특히 기업 내에 존재하는 LDAP 또는 AD와 같은 디렉토리 서비스를 활용하는 것입니다.
- 배치 및 Interactive SQL 쿼리에 대한 RBAC(Role-based Access Control)을 제공합니다. 예를 들어, Apache Sentry Permission은 Hive(HiveServer2)와 Impala에 적용됩니다.
CDH는 다음과 같은 유형의 접근 통제를 제공합니다:
- 디렉터리와 파일에 대해 전형직인 POSIX-스타일의 권한 제어: 개별 디렉터리 및 파일에는 단일 소유자와 그룹이 할당됩니다. 개별 소유자/그룹 할당은 사용 가능한 기본 사용 권한의 집합을 의미;파일 권한은 read, write 및 실행이며, 디렉터리의 권한은 하위 디렉터리에 대한 접근 권한을 결정하기 위한 추가 권한을 가지고 있습니다.
- HDFS용 ACL(Extended Access Control Lists): HDFS 파일에 대한 세분화된(fine-grained) 권한 제어 기능 제공 - 지정된 사용자나 그룹에 대해 서로 다른 권한 부여 가능
- Apache HBase는 column, column family 및 column family qualifier에 의한 다앙햔 오퍼레이션(Read, Write, Create, Admin)에 권한을 부여하기 위해 ACL을 사용하며, HBase ACL은 사용자 및 그룹 모두에게 부여됩니다.
Apache Sentry를 통한 RBAC(Role-based access control) : Cloudera Manager 5.1.x이상 부터 Sentry 권한은 정책(Policy) 파일 또는 데이터베이스 기반의 Sentry Service를 사용하여 구성 가능합니다.
- Sentry 서비스는 Sentry 권한을 구성하기 위한 권장 방식 입니다.
- Sentry를 구성하기 위해 Policy 파일 접근 방식도 사용가능 합니다.
Apache Sentry는 하둡용 역할(Role)기반 허가(Authorization) 모듈로 하둡 클러스터 내에서 인증된 사용자와 애플리케이션에게 하둡내 저장보관되어 있는 데이터에 대한 권한 제어 기능을 제공합니다. 현재 Sentry는 Apache Hive, Hive Metastore/HCatalog, Apache Solr, Impla 및 HDFS(Hive 테이블 데이터 파일에 대해서만 제한적으로 지원)과 같은 에코시스템에 대한 권한 모듈을 지원합니다. Sentry는 하둡 컴포넌트에 대한 플러그-인 권한 엔진으로 설계되었으며, 하둡 내의 다양한 유형의 데이터 모델에 대한 권한 기능을 제공합니다. Sentry를 활용하여 하둡 리소스에 대한 사용자나 애플리케이션 요청을 검증하기 위한 권한 규칙을 정의할 수 있습니다.
Architecture Overview
Sentry Components

Sentry는 다음과 같은 세 가지 구성 요소로 구성되어 있습니다:
Sentry Server: Sentry RPC 서버는 권한 메타 정보를 관리하며, 해당 메터 정보를 안전하게 조작하고 제공하기 위한 인터페이스를 제공합니다.
- Data Engine: 메타데이터 리소스나 데이터에 대한 접근 권한을 부여해야할 Hive나 Impala와 같은 데이터 처리 애플리케이션을 의미합니다. 데이터 엔진은 Sentry Plug-in을 로드하고 리소스 접근에 대한 모든 클라이언트 요청은 유효성 검증을 위해 Sentry Plug-in에서 인터셉트되어 라우팅 처리 됩니다.
Sentry Plugin: Sentry Plugin은 데이터 엔진에서 실행되며, Sentry 서버에 저장된 권한 메타데이터를 처리하기 위한 인터페이스 역할을 담당하며, Sentry 서버에서 조회된 권한 메타데이터를 사용하여 접근 요청을 평가하는 authorization policy engine을 포함하고 있습니다.
Key Concepts
- 인증(Authentication): 사용자를 식별하기 위한 자격증명(Credential)을 확인
- 권한(Authorization): 부여된 자원에 대해서만 사용자 접근을 제어
- 사용자(User): 사용된 인증 시스템에 의해 식별된 개인 사용자
- 그룹(Group): 인증 시스템에서 관리되는 사용자 집합
- 권한(Privilege): 특정 객체에 대한 접근을 허용하는 명령 규칙
- 역할(Role): 다중 접근 규칙을 사전에 정의한 템플릿으로 권한 집합(A set of Privilege)라고도 함
- 권한 모델(Authorization models): 권한모델의 대상이되는 객체(Object) 및 허용된 작업의 세분성을 정의합니다.
예를들어, SQL 모델에서 객체는 데이터베이스 또는 테이블을 의미하며, 액션은 Select, Insert 및 Create를 의미합니다. 또한, 검색 모델에서 객체는 Index, Config, Collections 및 Documents를 의미하며, 접근 모드는 쿼리 및 업데이트를 포함합니다.
User Identity and Group Mapping
Sentry는 사용자를 식별하기 위해서 Kerberos나 LDAP과 같은 기존 인증 시스템을 활용합니다. 이와 같은 전용 인증 시스템을 활용하면 Sentry는 다른 하둡 에코시스템에 매핑된 동일한 그룹 정보를 Sentry가 활용할 수 있다는 것을 의미합니다.
예를 들면, AD 시스템에서 재무팀이라는 그룹에 속한 Alice와 Bob사용자가 있다고 가정하면, Sentry에서는 최초 역할(Role)을 정의하고 해당 역할에 권한을 부여(grant privileges)합니다. 즉, Sentry에서는 Analytics라는 역할을 최초 정의한 뒤 이 정의된 역할에 Customer와 Sales 테이블에 대한 SELECT 권한을 부여하면 됩니다.
다음 단계는 인증 정보인 사용자(User)와 그룹(Group)에게 권한 정보(Role)을 부여하는 것입니다. 이전 예에서는 AD 그룹인 재무팀에 Analyst 역할을 부여합니다. 이는 재무팀 부서의 Bob과 Alice는 Customer와 Sales 테이블에 대한 SELECT 권한을 얻게 되는 것을 의미합니다.
Role-Based Access Control
RBAC(Role-based access control)은 일반적으로 기업내의 많은 사용자 및 데이터 객체에 대한 허가를 관리하는 강력한 매커니즘입니다. 기업내의 환경에서는 새로운 데이터 객체가 추가되거나 삭제될 수 있으며, 새로운 사용자가 추가하거나 조직간에 이동이 빈번하게 발생합니다. RBAC을 사용하면 이와 같은 변경을 좀 더 편하게 관리할 수 있게 해줍니다. 즉, Carol이라는 신입 사원이 재무팀에 입사하게 되면, AD에 재무팀에 이 신입 사원을 추가해 주면됩니다. 이는 Caral에게 Sales 및 Customer 테이블에 대한 접근 권한을 제공해 주는 것을 의미합니다.
Unified Authorization
Sentry의 또 다른 중요한 점은 통합된 허가 계층을 제공하는 것입니다. 접근 제어 규칙(Access Control Rule)이 단일화된 영역에서 정의되면, 다양한 데이터 접근 도구 전역에서 이를 활용하는 것입니다. 예를 들면, 이전 예에서 Analyst 역할을 부여하는 것의 의미는 Bob, Alice 및 재무 그룹의 다른 사용자에게 테이블 데이터 접근 권한을 부여하는 것이며, 해당 테이블의 데이터에 대한 접근은 Hive나 Impala와 같은 SQL 엔진 뿐만 아니라 MapReduce, Pig 애플리케이션 또는 HCatalog를 사용항 메타데이터 접근을 모두 포함한 것입니다.
Sentry Integration with the Hadoop Ecosystem
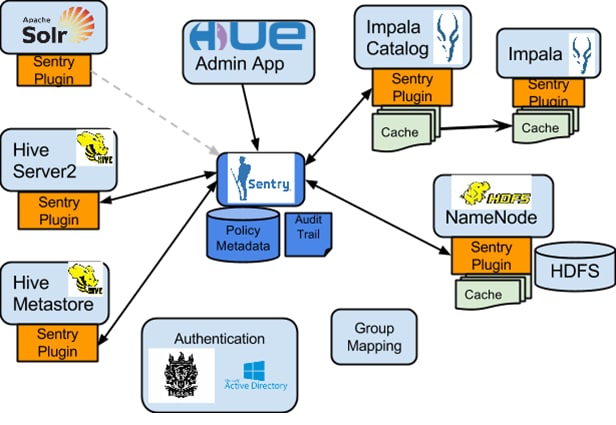
위의 그림과 같이 Apache Sentry는 다양항 하둡 컴포넌트와 상호 작용합니다. 중앙에서 Sentry Server는 허가(Authorization) 메타정보를 저장하고 해당 메타정보를 안전하게 제공하고 수정하기 위한 도구로 API를 제공합니다.
Sentry Server는 단지 허가에 대한 메타데이터만을 제공합니다. 실제 허가 결정은 Hive나 Impala와 같은 데이터 처리 애플리케이션에서 실행되는 정책 엔진(Policy Engine)에서 수행되며, 개별 컴포넌트들은 Sentry Plug-in을 로드하며, Sentry Plug-in의 역할은 Sentry Server와 통신을 하기 위한 서비스 클라언트와 권한 요청을 수행하는 정책 엔진(Policy Engine) 기능을 담당합니다.
Hive 및 Sentry
Consider an example where Hive gets a request to access an object in a certain mode by a client. 만일 Bob이 다음과 같은 Hive 쿼리를 제출(Submit)한 경우에는:
select * from production.salesHive는 Bob 사용자가 요청한 Sale 테이블에 대한 Select 접근 요청을 식별합니다. 이 시점에 Hive는 Sentry Plugin에게 Bob의 접근 요청의 유효성 검증을 요청하며, Sentry Plugin은 Sales 테이블에 관련된 Bob의 권한 정보를 회수한 뒤, 정책 엔진에서 해당 요청이 유효한지 여부를 판단할 것입니다.
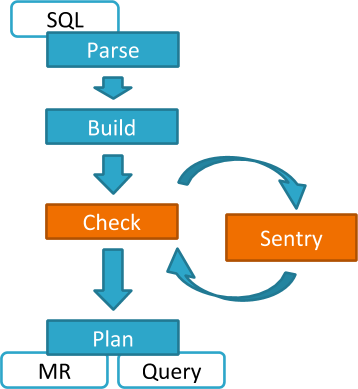
Hive는 Sentry 서비스 또는 정책 파일(Policy File) 방식 모두 지원하지만, 사용자 권한을 좀 더 쉽게 사용하기 위해서 Cloudera는 Sentry 서비스를 사용하는 것을 권장합니다.
Impala 및 Sentry
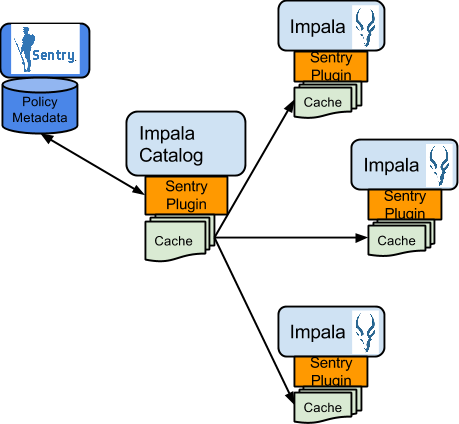
Impala 내에서의 허가 처리는 권한(Privileges)의 캐싱 방식에 차이점을 가지는 것 말고는 모두 Hive와 유사합니다. Impala의 Catalog Server는 스키마 메타데이터의 캐싱을 관리하며 스키마용 메타 정보의 변경사항을 모든 Impala 서버 노드에 전파하는 역할을 담당합니다. 이 Catalog Server는 Sentry 메타데이터 역시 캐시로 관리합니다. 이 때문에 Impala내의 서비스 또는 자원에 대한 권한 검증은 Impala 데몬이 실행되는 로컬에서 실행되기 때문에 Hive에 비해 빠르게 동작합니다.
Sentry-HDFS Synchronization
Sentry-HDFS 권한은 Hive warehouse 데이터에 중점을 둡니다. 즉, Hive나 Impala 내의 테이블의 부분인 데이터만을 대상으로 합니다. 이와 같은 통합은 Hive Warehouse 데이터를 대상으로 Hive/Impala 외의 Pig, MapReduce나 Spark와 같은 다른 구성요소에 대해서도 동일한 권한 검증으로 확대 적용하는 것을 목적으로 합니다. 이 관점으로 Sentry의 허가 기능은 HDFS ACL을 대체하는 것이 아닙니다. Sentry와 연관되지 않은 테이블들은 이전 ACL을 그래로 유지합니다.
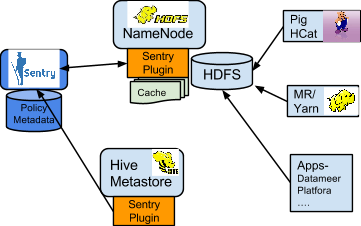
Sentry 권한(Privilege)을 HDFS ACL(Permission) 권한 매핑은 다음과 같습니다:
- SELECT privilege -> 파일에 대한 Read 권한.
- INSERT privilege -> 파일에 대한 Write 권한.
- ALL privilege -> 파일에 대한 Read 및 Write 권한.
NameNode는 Sentry 권한(Privilege)와 Hive 메타데이터를 캐쉬한 Sentry Plug-in을 로드합니다. 이는 HDFS가 동기방식으로 파일의 권한(Permission)과 Hive 테이블의 권한(Privilege)을 유지할 수 있게 해주는 것이며, Sentry Plug-in은 메타데이터의 변경사항을 동기화하기 위해 Sentry와 Metastore를 주기적으로 폴링합니다. 예를 들어, Bob이 Sales 테이블 데이터 파일로 부터 읽기 작업을 수행하는 Pig 작업을 실행한 경우에, Pig 작업은 HDFS로 부터 파일 정보를 얻기 위해 시도합니다. 이 시점에 NameNode의 Sentry 플러그인은 해당 파일이 Hive 데이터의 일부임을 감지하고 파일 ACL 기반으로 권한을 제어해야 함을 판단합니다. 결과적으로, HDFS는 Hive가 SQL 쿼리에 적용한 권한과 동일한 구너한을 이 Pig 클라언트에 적용합니다.
HDFS-Sentry Synchronization 기능을 사용하기 위해서는 반드시 Sentry 서비스를 사용해야 하며, 정책 파일 허가(Policy File Authorization)에서는 지원되지 않습니다.
Search 및 Sentry
Sentry는 데이터에 접속하고 컬렉션을 생성하는 것과 같은 다양한 검색 작업에 대한 제한을 설정할 수 있습니다. 데이터 자체의 제한은 해당 데이터에 접근하는 방식에 영향을 받지 않습니다. 예를 들면, Collection 내의 데이터에 접근에 대한 제한을 설정하면 이 적용 규칙은 CLI, 브라우저 또는 관리 콘솔과 같은 다양한 데이터 접속 방식에 대해 모두 적용됩니다.
검색을 사용하는 경우, Sentry 제한 규칙은 데이터베이스 기반의 Sentry 서비스나 HDFS 파일시스템에 저장된 정책 파일(hdfs://ha-nn-uri/user/solr/sentry/sentry-provider.ini)에 저장할 수 있습니다.
검색 업무에 적용된 Sentry는 다중 정책 파일이나 다중 데이터베이스를 지원하지 않습니다. 데이터베이스 기반의 Sentry 서비스 대신 정책 파일(Policy file)을 사용하는 경우에는 Sentry를 사용하는 개별 서비스에 대해 분리된 정책 파일(Policy file)을 사용해야 합니다. 예를 들면, Hive와 Solr 서비스는 동일한 정책 파일 권한을 사용하는 경우에는 잘못된 구성으로 권한 제어에 관련된 작업이 두 서비스에 대해 올바르게 동작하지 않을 것입니다. Search의 권한 제어 방식은 Sentry 서비스와 정책 파일 두 방식 모두 지원하지만 Cloudera에서는 Sentry 서비스를 사용할 것을 권장합니다.
Authorization Administration
Sentry Server는 Role과 Privilege를 안전하게 조작할 수 있는 API를 지원합니다. Hive 및 Impala는 권한을 관리하기 위한 SQL 문을 지원합니다. Sentry는 HiveServer2 및 Impala는 hive 또는 Impala와 같은 superuser로 실행한다고 가정합니다. Sentry에 대한 최 상위 권한을 시행하기 위해서는, 다음 예와 같이 관리자가 Beeline 또는 Impala-shell에서 권한 문을 실행하기 위해서는 반드시 superuser로 로그인해야 합니다:
GRANT ROLE Analyst TO GROUP finance-managers
Disabling Hive CLI
<property> <name>hadoop.proxyuser.hive.groups</name> <value>hive,hue</value> </property>
필요에 따라 Hive Metastore에 대한 접근 권한일 필요로 하는 더 많은 사용자 그룹에 대해서는 콤마 구분자를 활용하여 추가할 수 있습니다.
The Sentry Service
Sentry 서비스는 DBMS에 권한 메타 정보를 저장하고 권한 정보를 조회 및 수정가능한 인테페이스를 제공흐는 RPC 서버입니다. 인증 시스템으로 Kerberos를 지원하며, 실제 권한에 유효성을 Sentry 서비스에서 처리하지 않습니다. Hive, Impala 및 Solr 서비스는 Sentry 서비스의 클라이언트로 권한 처리를 Sentry를 사용하도록 구성한 경우 Sentry Privilege가 해당 서비스에 적용됩니다.
Sentry 서비스는 권한을 수정하기 위해 GRANT/REVOKE 문을 활용할 수 있으므로 기존 정책 파일(Policy File) 기반보다 사용자 권한을 쉽고 빠르게 처리할 수 있습니다.
Sentry에 의해 지원되는 객체 목록은 Server, Database, Table, URI, Collection 및 Config이며, Sentry에 의해 지원되는 권한은 다음과 같습니다:
Valid privilege types and the objects they apply to Privilege Object INSERT DB, TABLE SELECT DB, TABLE, COLUMN UPDATE COLLECTION, CONFIG QUERY COLLECTION, CONFIG ALL SERVER, TABLE, DB, URI, COLLECTION, CONFIG
Privilege Model
- 모든 사용자가 show function, desc function 및 show locks와 같은 명령어를 실행할 수 있습니다.
- 사용자는 자신에게 권한이 있는 테이블, 데이터 베이스, 컬렉션 및 구성 정보만을 확인할 수 있습니다.
- HiveQL 오퍼레이션을 실행하기 위한 URI에 대한 필요한 권한을 부여받은 사용자를 요구합니다. LOAD, IMPORT 및 EXPORT와 같은 오퍼레이션을 포함합니다.
- 특정 URI에 부여된 권한은 모든 하위 디렉터리에 재귀적으로 적용됩니다. 즉, 특정 디렉터리에 대한 권한은 상위 디렉터리에만 권한을 부여하면 됩니다.
- CDH 5.5 이상에서 Hive 및 Impala에 대해 테이블 대상으로 컬럼-기반의 접근 통제 기능이 추가되었습니다. 이전 버전에서는 Sentry는 테이블 단위의 권한 제어만을 지원했기 때문에, 사용자가 민감한데이터의 컬럼에 대한 접근을 제어하기 위해서는 민감한 컬럼 데이터를 보호하기 위한 View를 생성 후, 해당 View에 대한 권한을 Grant문을 활용하여 사용자에게 부여하였습니다. 이러한 관리적 부담을 해소하기 위해서, Sentry는 특정 테이블의 컬럼단위의 SELECT 권한을 할당할 수 있게 변경되었습니다.
User to Group Mapping
다음은 Sentry 내의 그룹 매핑에 대한 요약 정보를 보여줍니다:
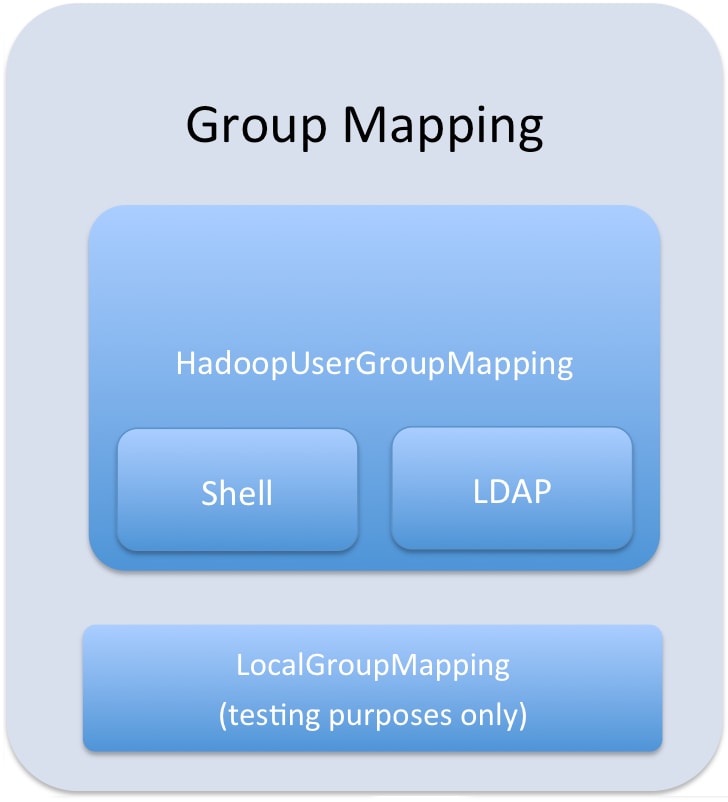
Sentry 서비스는 HadoopUserGroup 매핑만을 사용합니다.
Sentry Service Failure Scenarios
현재 CDH 버전에서는 Sentry의 이중화 구성이 지원되지 않기 때문에, Sentry 서비스에 장애가 발생한 상태에 Hive Warehouse에 접근을 시도한 경우, Hive, Impala 및 HDFS는 다음과 같이 동작할 것입니다:
- Hive: Hive warehouse에 대한 쿼리는 인증 에러와 함께 실패됩니다.
- Impala: Impala Catalog 서버는 Sentry 권한 정보를 캐쉬합니다. Sentry 서비스에 장애가 발생한 경우, Impala 쿼리는 Impala Catalog 서버에 캐쉬된 복사본을 통해 인증되어 지속적으로 사용가능하지만, CREATE ROLE 또는 GRANT ROLE과 같은 권한 DDL문은 실행되지 않습니다.
HDFS/Sentry Synchronized Permissions: HDFS 파일은 구성된 기간동안 동기화된 ACL의 캐시된 복사본을 사용한 뒤, NameNode ACL로 대치됩니다. 타임아웃 값은 Cloudera Manager의 hdfs-site.xml Safety Valve의 sentry.authorization-provider.cache-stale-threshold.ms 파라미터 옵션을 추가하여 수정할 수 있습니다. 기본 값이 60초로 설정되어 있기 때문에, 클러스터의 사이즈가 큰 경우 이 옵션의 값을 Sentry가 장애난 시점에 복구 가능한 시간 값으로 조정해야 합니다.
- Solr: Solr는 Sentry 서비스를 사용하지 않기 때문에 Sentry 서비스 장애에 영향을 받지 않습니다.
현재 CDH 버전에서는 Sentry의 이중화 구성이 지원되지 않기 때문에, Sentry 서비스에 장애가 발생한 상태에 Hive Warehouse에 접근을 시도한 경우, Hive, Impala 및 HDFS는 다음과 같이 동작할 것입니다:
- Hive: Hive warehouse에 대한 쿼리는 인증 에러와 함께 실패됩니다.
- Impala: Impala Catalog 서버는 Sentry 권한 정보를 캐쉬합니다. Sentry 서비스에 장애가 발생한 경우, Impala 쿼리는 Impala Catalog 서버에 캐쉬된 복사본을 통해 인증되어 지속적으로 사용가능하지만, CREATE ROLE 또는 GRANT ROLE과 같은 권한 DDL문은 실행되지 않습니다.
HDFS/Sentry Synchronized Permissions: HDFS 파일은 구성된 기간동안 동기화된 ACL의 캐시된 복사본을 사용한 뒤, NameNode ACL로 대치됩니다. 타임아웃 값은 Cloudera Manager의 hdfs-site.xml Safety Valve의 sentry.authorization-provider.cache-stale-threshold.ms 파라미터 옵션을 추가하여 수정할 수 있습니다. 기본 값이 60초로 설정되어 있기 때문에, 클러스터의 사이즈가 큰 경우 이 옵션의 값을 Sentry가 장애난 시점에 복구 가능한 시간 값으로 조정해야 합니다.
- Solr: Solr는 Sentry 서비스를 사용하지 않기 때문에 Sentry 서비스 장애에 영향을 받지 않습니다.
출처: Cloudera Enterprise 메뉴얼
'Big DATA > Cloudera' 카테고리의 다른 글
| How Does Cloudera Manager Work? (0) | 2017.02.01 |
|---|---|
| Cloudera - Oracle RAC 구성 (0) | 2017.01.10 |
| Sensitive Data Redaction (0) | 2016.11.14 |