1. 데이터 공유의 필요성
오늘날 모든 기업들은 매일 데이터를 통해 업무 성과를 추적하고, 데이터 기반으로 의사결정을 하며, 고객 성향을 파악할 때도 데이터를 활용합니다. 또한, 판매, 재고, 물류에 관련된 다양한 업무 영역에서 추세 예측을 위해 데이터를 활용합니다. 데이터는 부서 단위의 활용에서 벗어나 기업 내의 다양한 팀에서 데이터를 생성하고 소비하며, 외부 기간 및 고객으로부터 생성되는 데이터를 분석 또는 업무 목적으로 활용하거나 기업 내부의 데이터를 외부 기간에 제공할 필요가 있습니다. 오늘날 데이터는 기업 내/외부 조직간에 사용되는 중요한 리소스의 하나가 되었습니다. 하지만, 기업 내에서 생성된 데이터는 사일로된 데이터 분석환경에 의해 특정 부서 단위로 제한된 사용자에게만 제공되고 있습니다. 이처럼 사일로 된 데이터 환경의 다른 문제는 정형화된 제한된 데이터만을 수용할 수 있다는 것입니다. 데이터 레이크라는 개념은 앞서 살펴본 제한된 분석 환경에서 벗어나 기업 내에서 생성되는 모든 데이터를 단일 데이터 저장소에 통합하여 사용자에게 일관된 분석 환경을 제공하는 목적으로 탄생되었습니다. 하지만, 다른 기관 / 기업 또는 내/외부와 같이 복잡하고 산재되어 있는 데이터 환경에서는 데이터 레이크라는 개념을 초월하는 무언가가 필요해졌습니다. 일반적인 데이터 공유는 배치 / 실시간 또는 파일 / 스트리밍 이벤트와 같이 다양한 데이터 생성 요건과 더불어 소스와 타겟의 데이터 동기화에 대한 다양한 이슈가 발생하기 때문에 필요하지만 해결하기 어려운 과제입니다.
1.1 데이터 공유는 무엇인가?
데이터는 기업이 비즈니스를 운영하기 위해 구축한 업무용 애플리케이션, 웹 사이트(access log), 사물 인터넷(IoT) 장치 또는 무언가에 내장된 센서에서 생성될 수 있습니다. 현재 우리가 사는 환경에서는 잠재적으로 무한한 데이터가 생성되고 있습니다. IDC는 2025년까지 전 세계에서 생산되는 총 디지털 데이터가 180제타바이트(1제타바이트는 약 1조 기가바이트)로 증가할 것으로 추정했습니다. 불행히도 기존의 데이터 공유 방법은 데이터를 이동해야 하므로, 다양한 문제가 야기됩니다. 대다수의 기업에서 사용되고 있는 방식으로 방대한 양의 데이터를 공유하는 것은 기술적으로는 불가능하지 않더라도 비현실적입니다. 오늘날 많은 기업들은 기업 내부의 데이터를 통합하여 활용하는 것을 넘어서 외부의 데이터를 활용하여 비즈니스 운영을 향상 시키길 원하고 있습니다. 하지만 현실적으로는 외부 데이터에 접근하여 데이터를 활용하는 것은 매우 제한적이고 어렵다는 사실 또한 알고 있습니다. 따라서, 데이터 공유는 기업 내부의 조직 간 또는 외부 기업 간에 데이터에 대한 접근을 제공하는 것을 의미합니다. 데이터를 공유하는 기업을 데이터 공급자라고 합니다. 공유 데이터를 사용하려는 기업을 데이터 소비자라고 합니다. 모든 기업은 데이터 공급자, 데이터 소비자 또는 둘 다일 수도 있습니다.

그림 1-1은 전통적인 데이터 공유 방식으로, 데이터 공급자가 원본 데이터 복사하여 소비자에게 전송하는 데이터 공유 방식으로 오늘날 대다수 기업들이 이 방식을 사용하고 있습니다. 이와 같은 데이터 공유 방식에서 데이터 소비자는 데이터를 다운로드하여 해당 데이터를 기존 데이터와 결합하여 분석함으로써, 고객이 누구인지, 비즈니스가 얼마나 효율적으로 운영되는지, 비즈니스가 어떤 새로운 산업으로 나아가고 있는지에 대한 더 깊은 통찰력을 얻는 데 사용 되고 있습니다. 그러나 이 프로세스는 느리고 번거롭고 비용이 많이 들고 관리가 어렵기 때문에, 제한된 양의 데이터만을 공유할 수 있습니다. 그림 1-2는 최신 데이터 공유 방식으로 데이터 이동 없이 데이터를 공유하는 방법을 보여 줍니다. 데이터 공급자는 퍼블릭 클라우드 데이터 공유를 통해 데이터 소비자에게 실시간 읽기-전용 데이터 복사본을 제공합니다.

1.2 데이터 공유의 예
앞서 설명한 것처럼 기업 외부에 존재하는 데이터는 기하급수적으로 증가할 것입니다. IoT 데이터이든 다른 형태의 외부 데이터와 기업 내부 데이터를 함께 사용하여 분석하면, 전에는 불가능했던 새로운 비즈니스 인사이트를 발굴하여 사용할 수 있게 될 것입니다. 다음은 최신 클라우드 데이터 공유가 가능하게 하는 몇 가지 새로운 비즈니스 예시입니다:
- Data sharing to eliminate data silos: 기업 내부의 모든 데이터를 포괄하는 단일 데이터 플랫폼을 구축하고, 기업 내 부서 단위에 필요한 데이터를 공유하는 방식으로 기업 내의 사일로 된 분석 환경을 제거.
- Data sharing for business efficiencies: 실 운영 환경의 데이터를 기업 외부의 비즈니스 파트너와 공유하여 비용을 최적화하고 운영을 간소화하면서 동시에 고품질의 데이터 서비스를 제공.
- Data sharing as a product: 데이터 소비자가 외부 데이터를 참조하여 분석할 수 있도록 기업 내부의 운영 데이터에 대한 실시간 접근을 허용하여 필요한 데이터만을 활용. 데이터 제공자에게는 자사의 데이터를 활용한 데이터 판매 사업 기회 창출.
- Data sharing as a product differentiator: SaaS(Software-as-a-Service) 공급자는 B2B(기업 간 거래) 가입자 활동에서 생성된 페타바이트 규모의 데이터에 직접 접근하여, 이전에 사용할 수 없었던 더 많은 데이터를 활용하여 심층 분석을 수행
위에서 언급한 사용 사례를 가능하기 하기 위해서는 속도, 성능, 보안, 거버넌스 및 단순성을 갖춘 데이터 공유 기능이 필요합니다. 이러한 기능은 기존 데이터 플랫폼에서 제공하는 데이터 공유 방법으로는 불가능합니다.
1.3 어떻게 조직은 데이터를 공유해야 하는가?
전통적인 데이터 공유 기법은 데이터 공급자와 소비자 간의 데이터 공유를 위해 다양한 단계별 작업을 수행해야 하는 힘든 노력이 필요합니다. 이러한 프로세스는 일반적으로 비용이 많이 들고 관리 오버헤드가 발생할 수밖에 없으며 실제로 공유할 수 있는 물리적인 데이터양이 제한 될수 밖에 없습니다. 다음은 데이터 공급자와 소비자간의 데이터 공유를 위해 사용되는 전통적인 방식에서 활용되는 기술-셋을 설명합니다:
» Email: 데이터 파일이 공급자로부터 소비자에게 이메일로 전송.
» File Transfer Protocol (FTP): 데이터 파일은 두 컴퓨터 간에 또는 인터넷을 통해 공유 및 다운로드됨.
» Extract, transfer, load (ETL) software: ETL 소프트웨어를 활용하는 공급자의 데이터베이스에서 데이터를 추출하고 데이터를 변환한 다음 소비자 데이터베이스에 로드하는 방식.
» Online file sharing services: FTP와 유사하지만 데이터 파일 공유 및 다운로드는 인터넷 파일 전송을 통해서만 이뤄짐(네이버 대용량 파일 공유).
» Cloud storage: 공급자는 클라우드에 데이터를 저장하고 소비자에게 데이터에 액세스할 수 있는 자격 증명을 제공.
» Application programming interfaces (APIs): API는 데이터 전송을 시작하고 관리하는 데 사용.
그러나 소비자가 운영 데이터를 라이브 상태에서 직접 접근하면서 동시에 안전하고 관리되는 환경 내에서 만 해당 데이터를 바로 사용할 수 있다면, 데이터 공유는 어떻게 하면 될까요?
1.4 데이터 공유의 가능성..
실시간 데이터 공유를 통해 얻을 수 있는 혜택은 거의 무한합니다. 그렇다면 조직에서 새로운 데이터 공유를 활용해야 하는 이유는 무엇인가요? 다음은 몇 가지 일반적인 이유입니다:
» Improve the customer experience: 경쟁이 치열한 디지털 시장에서 개인화된 마케팅 캠페인을 통해 타겟 비즈니스 또는 소매 제품을 사용자에게 제공하기 위해서는 고객, 경쟁업체 및 업계 동향에 대한 더 깊은 이해가 필요합니다. 고객의 성향을 좀 더 잘 파악하기 위해서는 기업내에 보유하지 않아서 활용되지 않는 데이터를 수집해서 활용해야 하는 이유입니다.
» Streamline your business: 기업을 구성하는 여러 조직과 비즈니스 파트너와 데이터를 쉽게 공유하기 위해서는 단일 데이터 소스가 필요하며, 이를 통해 데이터 불일치로 야기되는 비용을 많이 절감할 수 있습니다. 또한, 기업은 이와 같은 데이터 기반으로 비즈니스 의사 결정을 할 수 있고 새로운 통찰력을 얻을 수 있습니다.
» Create new business assets from data: 데이터 공급자 내의 일부 데이터는 외부 데이터 소비자에게는 매우 가치 있는 자산이 될 수 있습니다. 새로운 개념의 데이터 공유는 현대화된 클라우드 데이터 플랫폼에서는 매우 간편한 방식으로 제공될 수 있습니다.
2. 전통적인 데이터 플랫폼내의 데이터 공유 문제에 대한 이해
2.1 데이터 공유에 대한 다양한 문제
다양한 내부 또는 외부 데이터 소비자와 데이터를 공유하는 경우(개별 고유한 데이터 공유 요구 사항 필요), 전통적인 데이터 공유 방식으로 이 요구사항을 충족하기에는 매우 어렵습니다. 데이터양이 증가할 때 마다 스토리지 추가 작업을 수행해야 하며, 복잡한 소프트웨어를 관리하고, 지연 시간과 성능 저하로 인한 어려움을 해결해야 하며, 과거 데이터 불일치 및 데이터 동기화에 대한 이슈를 해결해야 합니다. 즉, 오늘날 전통적인 데이터 플랫폼은 실시간으로 데이터를 공유해야 하는 요구사항을 고려하지 않고 설계되었습니다. 기존 데이터 공유와 관련된 문제의 규모를 이해하려면, 과거 데이터 공유를 위한 기술에 대한 장단점을 이해해야 합니다:
1. Email
- 장점: 유비쿼터스를 포함한 다양한 기기에서 이 표준 프로토콜을 지원하며, 이메일 작성 및 파일 첨부와 같은 간편한 방식 지원
- 단점: RDBMS와 같은 정형화된 대용량 데이터-셋 공유로 부적합하며, 첨부 파일 크기 제한으로 대용량 데이터 공유 시, 데이터 분할일 필요. 제한된 네트워크 대역폭에 의해 데이터 전송 속도가 느리며, 안전하지 않은 데이터 공유 방식으로 암호화 전송 기능 구현이 필요.
2. ETL
- 장점: 다양한 상업용 ETL 도구가 제공되며, 대다수의 솔루션은 고가용성을 보장. 정형 데이터 추출, 변환 및 로드 기능을 제공하며, 대용량의 정형화된 데이터의 복잡한 데이터 이동 및 변환 지원
- 단점: 고가의 ETL 솔루션을 구매해야 함. 데이터 변경 시에 대기 시간이 필요하며, 구현이 복잡하여 오랜 시간이 요구되고 EDW 시스템과 통합 및 배포를 위한 전문 인력을 보유해야 함. 변경 관리 및 스키마 변화에 민첩하게 대응이 불가능
3. 온라인 파일 공유 방식
- 장점: 고가용성 서비스가 필요하며, 사용 편의성 제공
- 단점: 관계형 데이터가 아닌 파일 기반의 데이터 공유에 적합하기 때문에 데이터 소비자는 사용을 위해 데이터 가공이 필요. 원천 데이터 변경에 따른 데이터 불일치 발생 가능성 존재
4. 클라우드 스토리지
- 장점 : 대규모 클라우드 업체에서 제공하는 다양한 서비스 활용 가능
- 단점: 클라우드 스토리지 기반으로 직접 쿼리 시, 낮은 성능 및 데이터 적재 후, 스키마 변경 관리 / schema evolution이 어려움. SQL DML 미지원
5. API 방식
- 장점: 프로그램 구현으로 일부 수동 작업을 완화할 수 있으며, 다양한 API 사용이 가능. 다양한 사용 사례 제공
- 단점: 데이터 전송 시, 데이터 유실 가능성이 존재하며, API 방식은 소량 데이터 교환에 적합하기 때문에 대용량 데이터 교환 시 성능 병목 현상 발생. 데이터 교환 성능을 개선하기 위해 높은 네트워크 대역폭을 요구하고 있어 높은 구축 비용 발생
6. FTP
- 장점: 오랜 기간 동안 광범위하게 사용된 프로토콜로 다양한 FTP 클라이언트 및 솔루션 제공
- 단점: 파일 기반의 데이터 공유 방식으로 데이터 표준화는 별도로 관리해야 하며, 수동 관리 필요. FTP 클라이언트 소프트웨어 및 서버에 관련된 서비스 구축이 필요하며 별도의 FTP 계정 관리에 대한 관리 오버해드 존재. 기본적으로 안전하지 않은 데이터 교환 방식으로 별도의 안전한 데이터 교환 방식 구축 필요
2.2 전통적인 데이터 공유 방식 : Time-to-Value 지연
기존의 데이터 공유 방법은 더 많은 지연을 야기하고 다음을 포함한 IT 팀의 더 많은 지원을 필요로 하는 문제를 야기할 수 있습니다.
- Handling increased data size: 공유 데이터 세트는 종종 원래 정의된 데이터 크기 이상으로 생성되어 데이터 추출 프로세스에 문제를 야기합니다. 데이터 변경을 자동화하기 위해서는 스크립트 언어를 사용해야 하기 때문에 추가 IT 지원이 필요할 수 있습니다. 또한, 데이터 변경이 발생한 경우, 데이터 소비자에서도 해당 변경사항을 반영해야 합니다.
- Decrypting sensitive data: 데이터에 민감 정보가 포함된 경우 출력 파일을 암호화, 마스킹 또는 수정해야 하므로 추가 IT 지원이 필요할 수 있으며, 데이터가 암호화된 경우 암호화 방식에 대해 데이터 공급자와 수신자가 사전에 암호화 표준 규격 및 암호화 키 교환에 대한 내용을 고려해서 데이터 공유 프로세스를 구축해야 합니다.
- file formats & schema 변경: 공유된 데이터의 형식이 변경되는 경우 공유 파일의 형식을 변경해야 합니다. 즉, 데이터 공급자 측에서 테이블 속성이 변경되면 데이터 소비자 측에서도 해당 변경을 반영해야 합니다.
위와 같은 상황이 지속해서 발생하면, 데이터 공급자와 소비자 모두에게 번거롭고, 느리고, 고통스러운 작업이 동반됩니다. 이 모든 상황은 데이터를 분석용으로 사용되기 전에 발생하기 때문에, 데이터를 통한 가치 실현을 지연시키는 주요 원인이 됩니다. 일반적으로 데이터 동기화에 대한 지연과 어려움은 앞서 설명한 이유 외에도 다음과 같은 원인들도 있습니다:
- Sharing data in real time: 데이터 공유 방식이 배치가 아닌 실시간인 경우, 더 많은 IT 자원 및 노력을 요구합니다.
- Cleaning data: 교환되는 데이터에 사전 정의된 형식이 아닌 경우가 종종 발생할 수 있습니다. 예를 들어, 데이터 추출 과정에서 정제되어야 하는 특수 문자 등이 포함될 수 있기 때문에, 데이터 제공자는 더 정교한 데이터 추출 프로세스를 구축해야 하므로 많은 IT 자원, 비용 및 데이터 교환의 지연이 발생할 수 있습니다.
데이터 동기화 과정에서 오류를 방지하기 위해서는 데이터 공급자와 소비자 모두는 데이터 전송을 모니터링해야 하며, 오류 발생 시 재처리 방안을 구현해야 합니다.
2.3 Computing Complexity Challenges
기존 방식으로 데이터를 공유하기 위해서는 복잡한 컴퓨팅 플랫폼이 필요해야 하며, 경우에 따라 컴퓨팅을 위한 노드를 확장해야 할 수도 있습니다. 이로 인해 아키텍처 복잡도는 증가되고 내/외부 인프라 및 관리 비용이 증가됩니다. 데이터 공유의 목표는 데이터 기반의 협업을 위해 비즈니스 파트너와 외부 고객을 포함한 내/외부 조직과 무제한의 데이터를 손쉽게 공유하는 것이여야 합니다. 비즈니스 모델이 데이터 수익화를 목적으로 하는 경우, 필요에 따라 개별화된 셀프 서비스 접근 및 보안을 통해 최대한 많은 양의 데이터를 소비자에게 공유되어야 하며, 손쉽고 빠른 공유 방식이 필요합니다. 클라우드 스토리지가 데이터 공유를 위한 해결책이라고 생각한다면, 다시 생각해야 합니다. 왜냐하면, 기본적인 클라우드 스토리지 서비스를 이용한 데이터 공유는 데이터를 활용하는 측면에서 비효율적이기 때문입니다. 클라우드 스토리지 서비스만을 활용해서는 데이터를 쿼리하거나 데이터 일관성을 보장할 수 있는 기능을 제공하지 않기 때문입니다. 또한, Hadoop 플랫폼은 고유한 복잡성 때문에 이에 대한 해결책이 될 수 없습니다.
2.4 전통적인 데이터 공유 방식 : 비즈니스 문제점
복잡하고 비용이 많이 드는 컴퓨팅 플랫폼과 결합된 번거롭고 복잡한 데이터 공유 방법은 데이터에 대해 협업해야 하는 조직에게 골칫거리입니다. 또한, 기존 데이터 웨어하우스에서 데이터를 추출하고 해당 데이터를 다른 조직으로 전송하는 데 필요한 처리 오버헤드로 인해 공유 데이터가 제공하는 가치가 지연됩니다. 또한 공유 데이터는 항상 정적 버전이며 즉시 부실해지기 때문에 데이터가 변경될 때마다 데이터 추출 및 전송 프로세스를 반복해야 합니다.
- 부서 내 데이터 공유: 일반적인 부서 내 데이터 공유 시나리오로는 1) "판매팀은 재무팀과 데이터를 공유하여 판매 및 수익을 추적하여 회사의 성과를 예측" 또는 2) "마케팅팀은 고객 데이터를 모니터링 및 분석하여 행동을 예측하고 수요 창출을 위한 애플리케이션을 지속해서 개선"과 같습니다. 조직 내의 기능 그룹이 데이터를 효과적으로 공유할 수 없으면 데이터 사일로가 발생하고 비즈니스 협업이 어려워집니다. 각 그룹은 자체 데이터 웨어하우스 또는 데이터 마트(기업 데이터 웨어하우스의 일부 데이터 복사본)를 유지 관리합니다. 데이터 사일로 및 데이터 마트의 무분별한 확산이 발생하고 IT 및 데이터 웨어하우스 팀에 불필요한 부담이 발생합니다.
- Business-to-business (B2B) 데이터 공유: 일반적인 B2B 간의 데이터 공유 시나리오는 1) "호텔 예약 웹사이트는 프로모션 및 가격 책정 프로그램을 개발하기 위해 호텔들로부터 예약 패턴과 트랜드 정보를 공유받음", 2) "대형 마트 회사는 공급 업체에 매장 판매 데이터를 제공하여 필요한 시점에 수요를 충족할 수 있도록 재고관리에 도움을 줌" 또는 3) "소매 업체는 매장 내 판매 데이터를 의류 업계에 공유하여 가장 인기 있는 트렌드 정보를 공유"와 같습니다. 오늘날 기업은 다른 회사와 데이터를 공유하든 다른 회사로부터 데이터를 공유받던 데이터에 대해 다른 회사와 공유해야 합니다. 만일 데이터 공유를 할 수 없다면, 기업 운영에 대한 효율성이 떨어지고 더 높은 비용가 낮은 생산성으로 운영될 위험이 있습니다.
- 데이터 마니티제이션(Data Monetization - 데이터 기반의 수입화): 공유 데이터로 부터 수익을 창출하는 대표적인 예는 휴대전화 위치 정보 및 사용 데이터를 수집하여 관련 데이터를 광고 대행사 또는 마케팅 회사와 공유하여 특정 소비자을 대상으로 고도로 타켓화된 캠페인을 실행하는 사례입니다. 데이터로부터 인사이트를 추출할 수 없다는 것은 데이터를 활용하여 상업적 가치를 극대화하는데 방해가 됩니다.
위의 사례에서 데이터 공급이 원활하게 진행되지 않는다면, 데이터 소비자는 데이터 기반으로 새로운 비즈니스 가치를 도출하는 것이 지연됨으로, 데이터 공급자에 대한 불만이 커질 수 있습니다. 더욱이 데이터를 공유하는 일반적인 방법은 변경사항을 데이터 공급자와 소비자 간에 즉시 동기화할 수 없기 때문에 데이터 소비자는 최신의 데이터가 아닌 왜곡된 데이터를 기반으로 분석을 수행할 수 있습니다. 이는 비즈니스 의사 결정에 대한 분석의 정확도가 떨어지거나 잘못된 의사 결정으로 야기할 수 있습니다.
3. 데이터 공유의 비즈니스 가치 인식
여기서는 데이터 공유 방법이 비즈니스를 어떻게 진화했는지, 데이터 공유가 모든 비즈니스에서 왜 중요한지, 기업이 내/외부에서 데이터를 공유하는 방법 그리고 클라우드 및 SaaS가 데이터 공유 모델을 어떻게 변화시켰는지에 대해서 살펴보도록 하겠습니다.
3.1 데이터 공유의 초기 단계 회고
오늘날 데이터 공유의 비즈니스 가치를 이해하기 위해서는 역사적 관점이 필요합니다. 얼마 전까지만 해도 모든 기업들은 자체 데이터 센터에서 업무용 애플리케이션을 위한 시스템을 구축하고 호스팅하는 것이 표준이었습니다. 애플리케이션의 유형으로는 재무, 마케팅, 판매, 인사와 같이 다양한 애플리케이션들이 해당됩니다. 불과 10년 전만 해도 대기업들은 자체 데이터 센터에 수백 개 이상의 독립된 애플리케이션을 구축하고 호스팅했으며, 이러한 애플리케이션들은 대다수 별도로 구축된 데이터베이스가 필요했습니다. 이처럼 개별적으로 구축된 데이터베이스는 분석을 위해 최적화되지 않았으며, 애플리케이션 간에 데이터는 공유되지 않았습니다. 또한, 이와 같은 애플리케이션에서 생성한 데이터들을 분석하기 위해서는 애플리케이션 DB를 담당하는 개별 부서별로 부서 전용의 독자적인 DW 시스템을 구축하고 데이터 마트를 생성하기 위해 소스 DBMS에서 ETL작업을 수행해야 합니다. 그런 다음, 조직 전체의 BI를 개발하거나 전사 데이터 기반으로 분석을 수행하려면, 부서별로 사일로 된 개별 데이터 마트에서 전사 EDW로 데이터를 ETL 프로세스를 통해 전송해야 합니다. 애플리케이션에서 생성된 데이터가 자체 DW를 거쳐 EDW로 통합되는 전체 프로세스는 매우 느리고 번거롭습니다. 데이터의 유형은 애플리케이션 유형에 따라 다양하기 때문에, 추가 모델링 및 데이터 변경 파이프라인이 필요합니다. 하지만, 기업에서 생성되는 모든 데이터는 최소한 기업 내의 데이터 센터 내에 존재하기 때문에 마음만 먹으면 해당 데이터에 접근할 수 있습니다. 결론은 어느 정도 내부 데이터 공유 없이도 어떤 회사도 자생할 수 있다는 것을 보여줍니다.
3.2 기업을 위한 데이터 공유의 비즈니스 가치
기업 내/외부와의 데이터 공유는 다음과 같은 네 가지 유형으로 정의될 수 있습니다:
» Across lines of business (LOBs): 기업 내의 다른 부서로부터의 데이터 공유
» Between enterprises: 비즈니스 파트너인 다른 회사에 기업 내 데이터 제공
» Between enterprises: 비즈니스 파트너 회사로부터의 데이터 공급
» Monetizing data: 데이터 소비자에게 실시간 데이터 공유; 데이터 소비자는 공유받은 데이터와 자신이 보유한 데이터를 통합하여 새로운 비즈니스 기회를 창출하거나 새로운 분석 용도로 활용
- Across lines of business (LOBs): 기업 내에서 부서들은 이메일, 엑셀 파일, 네트워크 파일 공유, API 방식 및 기타 방식을 통해 데이터를 공유합니다. 기업 전반에서 데이터를 공유하면 높은 수준의 BI 서비스를 활용할 수 있으며, 적기에 의사결정을 도와줌으로써 일상적인 비즈니스를 용이하게 해줍니다. 그러나, 데이터는 사일로 형태로 존재하며, 공유되지도 않고 있습니다. 기업 인수/합병, 네트워크 보안에 의한 데이터 접근 제약사항이나 기타 업부/기술적인 장벽으로 인해 대다수의 기업 환경에서는 기업 내의 모든 데이터를 모든 조직원에게 쉽게 공유할 수 없는 경우가 많습니다. 인프라의 이러한 물리적 또는 논리적 분리는 다양한 부서의 사용자들이 기업 내에서 사용 가능한 모든 데이터를 활용하여 데이터 기반의 새로운 인사이트를 발굴하는 것을 어렵게 만듭니다. 이러한 데이터 사일로 현상은 기업이 온-프레미스 환경에 구축된 DW나 클라우드로 마이그레이션 된 전통적인 DW 시스템에만 의존하여 데이터 분석을 수행할 때 자주 발생합니다.
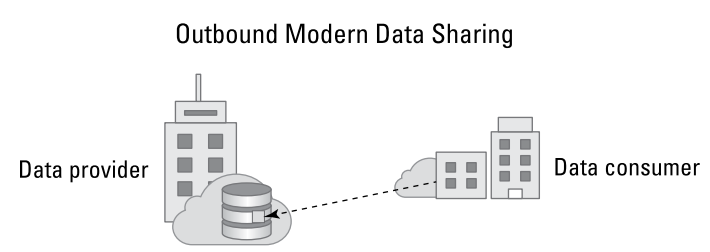
- Between enterprises(Outbound): 외부 데이터 공유는 말 그대로 비즈니스 파트너-쉽을 체결한 다른 회사와의 데이터 공유를 의미하며, 대부분의 비즈니스 파트너는 데이터 공유를 통해 비즈니스를 협력해 가고 있습니다. 그림 3-1은 특정 기업이 데이터 공급자로서 기업 내의 데이터를 비즈니스 파트너사에게 공유하는 방식을 설명합니다. 예를 들어, 데이터 공유 관계가 필요한 벤더-하청 업체 관계에서 하청 업체에서는 특정 품목의 재고를 언제 공급해야 하는지를 사전에 알아야 합니다. 즉, 공급업체는 벤더의 데이터를 기반으로 재고관리를 수행하여 기업의 마진을 최소화하여 재고 비용을 절감할 수 있으며, 필요하면 물품을 납품하여 더 견고한 비즈니스 관계를 유지할 수 있게 도와줍니다.
- Between enterprises(Inbound): 오늘날 점점 더 많은 기업들은 물류, 배송, 마케팅 또는 판매만을 전문적으로 수행하는 외부 서비스 회사들과 협력하고 있습니다. 예를 들어, 대형 소매업체는 타겟 고객에 대한 대량의 인구 통계 데이터를 수집한 뒤, 데이터 공급자로서 수집된 데이터를 데이터 분석 회사에게 제공하며, 데이터 분석 업체는 소매업체로부터 제공 받은 데이터를 기반으로 분석을 수행합니다. 그런 다음 그림 3-2와 같이 인바운드 데이터 공유 방식으로 소매업체에게 분석한 결과를 제공합니다.

- Monetizing data: 오늘날 데이터는 일상적인 협업보다 더 중요할 수 있습니다. 이제 데이터는 새로운 비즈니스의 자산이 되었습니다. 따라서, 데이터는 데이터를 활용하려는 조직에 따라 다양한 유형의 가치를 제공할 수 있습니다. 모든 자산과 마찬가지로 데이터에는 가치가 있습니다. 데이터를 활용하여 수익화하기 위해 데이터 공급자는 그림3-3과 같이 데이터를 사용하여 자신의 비즈니스 목표를 달성할 수 있는 소비자에게 데이터를 판매할 수 있습니다.

공유 데이터를 통해, 데이터 소비자는 별도로 데이터 수집 필요 없이 단순하게 데이터를 사용할 수 있습니다. 데이터 소비자는 공유된 데이터를 직접 분석하거나 보유한 다른 데이터와 결합하여 데이터의 가치를 개선함으로써 비즈니스적인 혜택을 얻을 수 있습니다. 그러나, 데이터 자체의 가치를 제대로 활용하기 위해서는 데이터의 물리적 이동 없이 데이터를 손쉽게 접근하여 사용할 방법이 필요합니다. 전통적인 데이터 공유 방식은 고비용에 다양한 위험 요소가 실제로 존재하며, 관리 유지하기에 매우 어렵습니다. 데이터 수익화를 제대로 실현하기 위해서는 데이터 공급자와 데이터 소비자 간에 데이터 공유를 쉽고, 안전하고, 저렴하게 할 수 있는 셀프-서비스 비즈니스 모델을 필요로 합니다.
4. 실시간 데이터 공유를 위한 현대화된 클라우드 DW 아키텍처
여기서는 클라우드 환경에서 제공되는 현대화된 DW 아키텍처가 데이터 공급자와 소비자 간에 발생했던 기존 데이터 공유 문제를 어떻게 해결 할 수 있는지를 알아보고, 현대화된 클라우드 DW 환경에서 데이터 소비자에게 실시간 데이터 접속을 안전하고 관리되는 방식으로 제공하기 위한 기능을 활성화하는 방법을 살펴보도록 하겠습니다.
4.1. 최신 데이터 공유 방식: 오래된 것은 과감하게 버리고 새로운 것은 그대로 유지
이전에 논의했던 것과 같이, 데이터 공유는 다양한 과제를 포함하고 있지만, 전통적인 데이터 공유 방식은 근본적으로 데이터 소비자가 공급자의 데이터에 접근할 수 있는 문제만을 해결하는 데 집중했습니다. 기존 DW와 데이터 레이크는 데이터를 사용할 수 있도록 설계되었지만, 데이터 공유를 고려하지 않고 설계되었기 때문에 오늘날 대다수의 고객사에서 요구하는 데이터 공유 기능을 제공할 수 없습니다.
- 기존 데이터 공유 방식의 제약 사항: 전통적인 데이터 공유 방식은 매우 느리기 때문에 기업 환경에서 신속한 실행 능력을 저하하는 주요 원인이 됩니다. 또한, 보안 및 거버넌스의 부족은 무엇보다도 기존 DW와 데이터 레이크 아키텍처가 그림4-1과 같이 데이터 소비자의 무제한 동시 접속을 수용할 수 없으며, 데이터 공급자에서 발생한 실시간 데이터 변경을 번거로운 작업 없이 소비자에게 제공할 수 없습니다. 이로 인해 데이터 소비자는 과거(Static) 데이터를 최신 데이터로 오인할 수 있는 위험성을 가지고 있습니다. 근본적인 해결책이 없기 때문에 데이터 제공자와 소비자는 항상 데이터를 공유하고 최신 정보로 동기화하는 데 어려움을 겪고 있습니다. 이러한 제약사항은 데이터를 기반으로 새로운 비즈니스 기회를 발굴하거나 비즈니스 모델을 데이터 수익화로 전환하는 데 걸림돌이 됩니다.

- 최신 데이터 공유의 새로운 비즈니스 기회: 클라우드 기반의 현대화된 DW에서 제공하는 데이터 공유 기능을 통해, 모든 사용자는 기업 내/외부 사용자에게 데이터 소비자의 규모와 관련 없이 DW에 저장된 모든 데이터에 대한 실시간 접근을 단 몇 분 만에 활성화하여 제공할 수 있습니다. 기업 내/외부 사용자들에게 데이터를 공유하여 더욱 다양한 데이터를 기반으로 분석 업무를 수행하고, 데이터-기반 이니셔티브, 새로운 비즈니스 모델 및 신규 수익원을 쉽게 활성화하는 데 도움이 됩니다. 그림 4-2는 최신 데이터 공유가 제공하는 혜택을 보여주고 있습니다. 최신 데이터 공유를 통해, DW에 저장된 데이터를 즉시 공유하여 실시간으로 사용할 수 있습니다. 현대화된 클라우드 DW 아키텍처에서 공유 데이터에 대한 쿼리 속도는 기하급수적으로 빨라지고 데이터 공유용 컴퓨팅 리소스와 무제한의 스토리지는 지속해서 강화되고 있습니다. 현대화된 클라우드 DW의 아키텍처와 기능은 데이터 공유 플랫폼으로 그 기능을 확장하였습니다. 모든 기업들은 안전하고 관리되는 환경의 라이브 데이터(구조화 및 반 구조화 데이터)에 대한 읽기-전용 접근 권한을 부여할 수 있습니다. 데이터 소비자는 다른 조직이나 회사의 데이터와 자신이 보유한 데이터를 결합(JOIN)하여 데이터 분석을 강화하고 심화시킬 수 있습니다. 멀티-테넌트 클라우드 DW-as-a-service의 확장성, 탄력성 및 유연성과 같은 특징으로 다양한 데이터 소스의 데이터를 저장하고 수 많은 데이터 소비자에게 관련 데이터를 쉽게 빠르게 공유할 수 있습니다.

- 간편한 데이터 공유: 최신 클라우드 데이터 공유는 데이터 게시, 엑세스 및 제어를 위한 기본 메커니즘만 제공하는 기존 방식의 동기화 지연, 비용 증가와 같은 위험 요소들을 모두 제거합니다. 최신 데이터 공유는 "1) 스토리지와 컴퓨팅 분리, 2) 멀티-테넌트 메타데이터, 보안 및 트랜잭션 관리 기능 제공 및 3) 무제한 동시 작업 수용"이라는 세 가지 주요 아키텍처 혁신을 기반으로 구현되었습니다.
- 데이터 공유를 위한 복사 및 이동 제거: 최신 데이터 공유는 안전하게 관리되고 제어되는 환경에서 라이브 데이터에 대한 실시간 및 바로 연결 기능을 제공해야 합니다.
- 바로 사용(ready-to-use)할 수 있는 데이터 제공: 데이터 소비자는 DW의 모든 기능을 사용하여 단 몇 분 안에 공유된 데이터를 분석 할 수 있어야 하며, 공유된 데이터와 자신이 보유한 데이터를 함께 사용할 수 있어야 합니다. 보안, 거버넌스, 데이터 스키마 및 메타데이터는 현대화된 데이터 웨어하우스에서 모두 제공됩니다.
- 추가 투자 비용 없이 데이터 공유 설정: 최신 데이터 공유는 데이터 소비자가 데이터를 복사하거나 이동하지 않고 데이터 공급자로부터 직접 데이터를 공유받기 때문에 공유된 데이터를 저장하기 위한 별도의 인프라 구축이 불필요하기 때문에 중복 투자 비용을 최소화합니다.
- 무제한 데이터 공급자 및 소비자와 데이터 공유 가능: 다중 사용자가 동일한 데이터에 접근하여 동시에 다양한 분석 업무를 처리하기에 제한된 전통적인 DW와 달리 현대화된 클라우드 DW는 완벽한 트랜잭션 무결성 및 데이터 일관성으로 무제한의 데이터 공급자와 소비자를 수용할 수 있습니다.
- 스토리지, 컴퓨팅 및 서비스의 분리: 그림4-3과 같이 스토리지와 컴퓨팅 리소스의 분리는 최신 공유 아키텍처의 근간이 되는 부분입니다. 모든 데이터는 데이터 유실이 없이 최적화된 형식으로 클라우드에 저장됩니다. 현대화된 클라우드 데이터 웨어하우스에 저장된 데이터의 단일 복사본(단일 소스)은 여러 개의 컴퓨팅 클러스터에서 동시에 접근할 수 있으며, 컴퓨팅 클러스터는 격리된 실행 환경을 제공하기 때문에 기업 내에서 분석과 같은 워크로드를 원하는 수만큼 수행할 수 있습니다. 스토리지와 컴퓨팅 리소스의 분리는 데이터 공유의 핵심입니다. 이를 통해 데이터 소비자는 공유된 데이터에 직접 접속할 수 있으며, 이 경우 데이터는 직접 데이터 소비자에게 이동하지 않기 때문에 데이터를 위한 별도의 스토리지 비용이 불필요하며, 데이터 공급자는 소비자가 공유된 데이터를 분석하는데 사용되는 컴퓨팅에 대한 비용을 지불하지 않습니다.

- 멀티 테넌트 메타데이터 및 트랜잭션 관리: 일관된 서비스 경험 및 성능과 안전하게 공유된 데이터를 사용하기 위해서는 데이터에 대한 접근을 포함한 모든 데이터 소비자 간의 조정 작업이 필요로 합니다. 서비스 계층은 글로벌 메타 정보, 트랜잭션 및 보안과 같은 기능들이 이 계층에서 관리되기 때문에 최신 데이터 공유 아키텍처의 핵심 부분입니다. 그림 4-4와 같이 DW에 포함된 모든 데이터베이스 요소 및 객체에 대한 데이터를 추적, 기록하고 접근하는 관리 기능을 제공하기 위해 서비스 계층이 필요로 합니다. 또한, 서비스 계층은 모든 데이터 공급자와 소비자 간에 트랜잭션 일관성을 제공하여 모든 사용자가 항상 최신 데이터만을 사용할 수 있게 해줍니다. 데이터 공급자는 공유된 데이터를 언제든지 변경할 수 있습니다. 마찬가지로, 데이터 변경에 대한 트랜잭션이 완료되면, 모든 데이터 소비자들은 데이터 공급자가 변경한 최신 데이터에 대해 즉시 쿼리하여 사용할 수 있습니다. 데이터 공유의 또 다른 이점은 데이터 소비자는 필요한 데이터를 찾기 위해 데이터 프로바이더의 전체 데이터-셋을 스캔할 필요 없이 공유 데이터에 대해서만 즉시 접근할 수 있다는 이점도 제공됩니다. ACID는 여러 SQL문에 대한 트랜잭션 처리, 애플리케이션 오류 및 하드웨어/소프트웨어 장애가 발생한 때도 관계형 데이터베이스에서 데이터 정합성을 유지하고 확인하기 위한 처리 일관성 모델입니다. ACID의 속성은 다음과 같습니다:
- 일관성 - Consistency: 특정 트랜잭션의 작업이 완료되면 데이터베이스의 상태가 변경된 상태로 유지됩니다.
- 지속성-Durability: 단일 트랜잭션의 작업이 commit 되면, 커밋 상태로 유지됩니다.
- 격리성-Isolation: 여러 개의 개별적인 트랜잭션 작업은 트랜잭션 처리를 위해 단일 데이터에 동시에 접근하여 처리하지 않으며, 여러 트랜잭션 작업 간의 데이터 점유를 위한 경합이 발생되기 때문에 개별 트랜잭션 작업은 순차적으로 실행되는 것처럼 느껴집니다.
- 원자성 - Atomicity (“all or nothing”): 단일 트랜잭션이 완료되려면 트랜잭션 내의 모든 작업은 성공적으로 처리되어야 합니다. 트랜잭션 내의 단 하나의 작업이 실패하는 경우, 전체 트랜잭션 내의 모든 작업은 롤백처리되고 데이터베이스 내의 데이터 상태는 변경되지 않은 상태로 유지됩니다.

- Unlimited concurrency: 전통적인 DW의 아키텍처는 모든 사용자가 클러스터의 리소스를 경합하여 작업을 처리하는 방식이기 때문에, 운영 담당자는 사용자 워크로드 패턴을 파악하고 클러스터에서 수행할 수 있는 워크로드를 제한하는 것과 같은 최적화 작업을 통해 일관된 사용자 경험을 제공하는 어러운 작업을 수행해야 합니다. 이에 대조적으로, 현대화된 클라우드 DW에서 제공하는 현대화된 데이터 공유를 통해 그림 4-5와 같이 수많은 동시 사용자가 공유 데이터에 동시에 사용할 수 있습니다. 동시 사용자를 유연하게 수용하기 위한 자동 확장 기능은 관리자 개입 없이 추가적인 실행 환경을 자동으로 확장하여 다중 사용자에 대한 동시 쿼리 작업에 대한 일관된 사용자 경험을 제공하며, 이 기능은 공유 데이터에도 적용됩니다.

4.2. 최신 클라우드 데이터 공유 사용
최신 클라우드 데이터 공유는 현대화된 클라우드 데이터 웨어하우스-서비스의 모든 사용자가 데이터베이스 테이블 및 뷰에 액세스할 수 있다는 것을 의미합니다. 또한, 현대화된 클라우드 데이터 웨어하우스-서비스는 데이터 공급자가 데이터베이스 테이블에 대한 세부적인 접근제어를 통해 공유함으로써, 공유된 데이터는 안전하게 관리되는 뷰를 통해 데이터 소비자에게 제공됩니다. 데이터 소비자는 공유된 데이터에 대한 접근 권한이 부여된 경우에만 공유된 데이터를 사용할 수 있습니다. 즉, 데이터 공급자가 자신의 데이터-셋의 일부 데이터에 대한 공유를 생성하면, 데이터 소비자는 공유된 데이터만을 사용할 수 있습니다.
데이터 공유의 핵심은 모든 데이터베이스의 객체들이 현대화된 클라우드 데이터 웨어 하우스의 글로벌 메타데이터 관리 서비스에 의해 관리되고 조정되기 때문에 데이터 공유를 위한 데이터 복사 및 이동 없이 즉각적인 접속이 가능합니다.
동작 원리
데이터 공급자: 데이터를 공유하기 위한 첫 번째 작업은 특정 데이터 소비자에게 공유할 데이터베이스 테이블 또는 뷰를 지정하는 것입니다. 이 작업은 데이터 공유 객체, 즉 실제 데이터베이스와 공유된 데이터베이스 객체에 대한 참조 값을 가진 사실상 "empty shell(빈 자료구조)"를 통해 이뤄집니다. 데이터 공유는 공유(share) 객체를 생성하고 관리하기 위한 DDL(Data Definition Language) 명령어를 제공하는 현대화된 클라우드 데이터 웨어하우스 환경의 first-class 객체를 의미합니다.
데이터 공유에 관련된 명령어로는 "create share", "alter share" 및 "drop share" 등의 명령어를 제공하며, 접근 권한을 정의하는 명령어는 "grant" 및 "revoke privileges"와 같은 명령어를 포함하고 있습니다.
일단 공유 객체가 생성되면, 데이터 공급자는 공유할 특정 데이터 베이스 및 데이터베이스 객체에 대한 접근 권한을 부여해야 합니다. SQL 문은 다음과 같습니다:
1. 공유(share) 객체 생성 - 다음 예시는 "sales_s"라는 빈 공유 객체를 생성하는 것입니다:
create share sales_s;
2. 공유 객체에 대한 권한을 추가: 기본 객체 내의 객체들에 대한 사용 권한을 부여하기 전에 기본 객체에 대한 권한을 부여해야 합니다. 예를 들어, 테이터베이스에 포함된 스키마에 대한 사용 권한을 부여하기 위해서는 사전에 데이터베이스에 대한 권한을 부여해야 합니다. 데이터 공유 소비자를 추가하기 전에 공유할 데이터에 대한 모든 권한을 부여하는 작업을 완료해야 합니다. 다음 예는 데이터-공유 객체에 "sales_db" 데이터 베이스,"aggregates_eula" 스키마 및 "aggregate_1" 테이블에 대한 권한을 부여하는 작업입니다.
grant usage on database sales_db to share sales_s;
grant usage on schema sales_ db.aggregates_eula to share sales_s;
grant select on table sales_ db.aggregates_eula.aggregate_1 to share sales_s;
3. 다음 명령어를 통해 공유 객체에 구성 내용을 확인:
show grants to share sales_s;
4. 공유하고자 하는 데이터 소비자에게 공유에 대한 접근 권한을 부여: 다음 예는 "sales_s" 공유 객체를 다른 현대화된 클라우드 데이터 웨어하우스 환경에서 사용할 수 있도록 구성하는 방식입니다:
alter share sales_s add accounts=data_consumerA, data_ consumerB;
"data_consumerA" 및 "data_consumerB"는 이제 공유된 데이터를 자신의 환경에서 사용할 수 있습니다.
앞에서 설명한 단계는 데이터 공급자가 데이터를 공유하고자 하는 데이터 소비자들에게 공유를 쉽게 구성하고, 데이터 소비자는 데이터 공급자에서 제공하는 데이터를 라이브로 활용할 수 있음을 보여줍니다.
4.3. 안전한 뷰를 활용한 공유 데이터에 대한 접근 통제 및 제어
만일 데이터베이스 내에 민감한 정보가 있는 경우 어떻게 해야 하나요? 데이터 공유 기능 및 클라우드 환경용으로 구현된 현대화된 데이터 웨어하우스를 사용하면, 전체 데이터베이스 또는 테이블에 대한 모든 데이터에 대한 공유를 제어할 수 있습니다. 특정 테이블 일부에 엄격한 보안 및 기밀 유지 정책이 적용되는 경우, 이 테이블에 있는 모든 데이터를 그대로 공유하면 민감한 정보가 함께 공유됩니다. "secure view"라는 명령어 유틸리티를 통해, 그림 4-6과 같이 현대화된 클라우드 데이터 웨어하우스는 공유할 데이터에 대한 사용자 접근을 제어하고 보안 침해를 방지할 수 있습니다.

예를 들어, 온라인 소매업체가 적정 수준의 재고 관리 계획을 수립하기 위해서는 그들은 상품 및 판매 데이터를 유통업체와 공유해야 합니다. 그러나, 판매 데이터가 포함된 데이터베이스의 테이블에는 고객에 관련된 민감한 정보가 포함되어 있기 때문에 보호되고 공유되어서는 안 됩니다. 앞서 설명한 온라인 소매 업체의 요구사항을 보안 뷰(Secure View)를 사용하여 충족하기 위해서는 이전에 설명한 SQL 구문에 따라, "sales_db" 데이터베이스용 "sales_s" 데이터 공유 객체를 생성합니다. 이 예에서는 "sales_db"와 "sales_s" 객체는 이미 생성하였다고 가정합니다. "sales_db"용 스키마의 이름은 public이며, 하위에 "unitsales" 테이블은 "customerid, sku, date, qty"의 스키마 구조로 생성되어 있으며, 데이터가 저장되어 있습니다. 유통 업체와 새로운 재고 계획을 수립해야 하는 경우, unitsales 테이블에 대한 접근 권한을 제공해야 하지만, "customerid"라는 민감한 고객 정보는 공유하지 않고 싶습니다. 따라서 유통 업체를 위한 "unitsales" 테이블을 사용하여 "distributor_sales_data"라는 보안 뷰(Secure View)를 생성합니다.위에 설명한 내용을 위해 다음 단계를 수행해야 합니다:
1. 보안 뷰(Secure View) 생성: 공유를 위한 원본 테이블이 이미 생성되어 있다고 가정하면, 다음 단계는 "unitsales" 테이블에 대한 보안 뷰를 생성해야 합니다.
create secure view sales_db. public.distributor_sales_data as select sku, date, qty from sales_db.public.unitsales;
보안 뷰는 민감 정보를 포함한 customerID 컬럼을 포함하지 않고, sku, date 및 qty에 대한 데이터만이 해당 보안 뷰에 포함되어 있습니다.
2."sales_s" 공유 컨테이너에서 보안 뷰용 권한을 부여:
grant usage on database sales_db to share sales_s;
grant usage on schema sales_db.public to share sales_s;
grant select on view sales_db.public. distributor_ sales_data to share sales_s;
이는 공유(컨테이너)인 "sales_s" 객체에게 "distributor_sales_data" 보안 뷰에 대한 권한을 부여하는 것을 의미합니다.
3. 공유 객체에 대한 내용을 확인:
desc share sales_s;
4. 유통 업체에게 공유 객체에 대한 접근 권한을 부여: 유통 업체 역시 현대화된 클라우드 웨어하우스 사용자라고 가정
alter share sales_s add accounts=;
5. 전체 공유 객체를 확인:
show shares;
앞의 예에서 알 수 있듯이 데이터 공급자는 데이터를 쉽게 공유하는 동시에 데이터 소비자의 데이터 접근을 보안 뷰를 통해 제어할 수 있는 것을 알아봤습니다. 민감한 데이터는 보호되며 데이터 소비자는 데이터를 복사하거나 이동할 필요 없이 자신의 데이터 분석을 위해 민감하지 않은 데이터에 대해서만 접근하여 사용할 수 있습니다. 무제한 데이터 공유 및 멀티-테넌트 기능을 통해 최신 데이터 공유는 클라우드용으로 구축된 데이터 웨어하우스의 기능을 확장하여 새롭고 창의적인 방식으로 기업 내부의 데이터 공유 관계를 1:1, 1:n 및 n:n으로 쉽게 구축할 수 있습니다.
5. 최신 방식의 데이터 공유 영향도 평가
최신 데이터 공유를 통해 실시간 협업을 가능하게 하는 방법, 최신 데이터 공유 아키텍처를 가능하게 하는 기술 및 추세, 그리고 최신 데이터 공유를 통해 기업이 데이터를 통해 새로운 비즈니스 자산을 신속하게 생성하는 방법을 살펴보도록 하겠습니다.
5.1. 데이터 협업에 대한 최근의 접근 방식
전통적으로, 데이터 공유는 그림 5-1과 같이 데이터 공급자와 소비자 간에 물리적인 데이터의 이동을 의미했습니다. 이 방식은 다음과 같은 다양한 문제를 야기합니다:
- 공유해야 하는 데이터는 연속적인 것이 아니라 체크포인트와 같은 단일 시점의 데이터 복사본이 존재해야 하며, 시간에 경과에 따라 빠르게 동기화가 되지 않기 때문에 최신의 데이터가 아닌 오래된 데이터를 사용할 가능성이 존재합니다.
- 기업 내의 사일로 된 여러 시스템에 걸쳐 동일 데이터에 대한 데이터 중복이 발생합니다.
- 기업 내의 존재하는 모든 데이터에 대한 단일 데이터 소스 또는 통합된 데이터 거버넌스가 존재하지 않습니다.
- 데이터는 구축 환경에 따라 최신의 데이터가 아닐 수 있기 때문에, 중요한 비즈니스 결정은 부정확한 데이터를 기반으로 수행됩니다.
- 여러 데이터-셋의 형상 관리가 점점 더 어려워지기 때문에 운영 관리의 부담이 되며, 운용 비용이 증가될 수 밖에 없습니다.
- 중복 데이터가 기업 내/외부의 여러 위치에 저장됨으로써, 스토리지 요구 사항 및 비용이 증가합니다.
- 잠재적인 데이터 침해 및 우발적 데이터 손실/노출 위험으로 인해 데이터 보안, 모니터링, 데이터 복구와 같은 운영 비용을 포함하여 기업 브랜드 가치 하락, 고객 이탈, 법정 소송, 포렌식 분석과 같은 비용이 함께 증가합니다.
- 법정 소송 지원을 위한 요구사항을 충족하기 위해는 기업 내/외부의 여러 데이터 소스를 식별, 검색 및 생성에 관련된 전자 증거 자료를 관리해야 하므로 이에 관련된 비용이 증가됩니다.

최신 데이터 공유는 데이터 소비자에게 공유할 데이터에 대한 실시간 접속을 제공함으로써, 기업 내/외부에서 빠르고 비용 효율적이며 안전한 공동 작업을 가능하게 합니다.
5.2. The Democratization of Computing
엔터프라이즈급 컴퓨팅 성능은 지속해서 진화하며, 점점 빠르고 저렴해 지고 있습니다. 클라우드는 이러한 하드웨어 진보를 가속화하여 모든 규모의 기업들이 클라우드 환경에서 무제한 컴퓨팅 리소스를 대규모로 쉽게 사용할 수 있게 해줍니다. 이러한 강력한 성능 덕분에 많은 분석에 관련된 연산 작업들은 IT 관리자 개입 없이 현업 사용자들이 직접 수행할 수 있게 되었습니다. 업무 분석가들은 대용량 데이터-셋을 대상으로 고급 분석을 수행할 수 있게 되었으며, 데이터 과학자는 예측 분석을 실행하고 AI/ML 기반으로 알고리즘을 개발할 수 있습니다. 비즈니스 경영진은 정확한 데이터 기반의 분석 대시보드를 사용하여 정확한 의사결정을 하며, 제품 관련 부서는 신제품 및 서비스 출시 기간을 단축할 수 있습니다.
5.3. 데이터 기반의 비즈니스 의사 결정
오늘날 대다수의 기업들은 고객 관점의 맞춤형 서비스를 제공하기 위해서 다양한 채널(예: 웹 사이트, 모바일 장치, PoS 단말기, 콜 센터 등)에서 데이터를 수집하는 다채널 접근 방식이 필요합니다. 전통적인 DW는 다양한 시스템으로 부터 데이터 수집이 어려울 뿐만 아니라 서로 다른 채널에서 수집된 데이터의 형식이 모두 상이하기 때문에 데이터의 관계나 의미를 제대로 파악할 수 없었습니다. DB 테이블, 엑셀 파일, JSON(JavaScript Object Notation) 및 기타 형태의 반구조화된 데이터와 혼합된 기타 형태의 구조화된 데이터는 기존 DW 기술로 해결하기 굉장히 어렵습니다. 반정형 데이터는 소셜 미디어 사이트, 클릭-스트림, 모바일 장치 및 사물 인터넷 장치와 같은 최신 데이터 소스에서 생성된 데이터를 포함하며, 기존의 구조화된 데이터 표준을 준수하지 않습니다. 그러나, 오늘날 비즈니스 환경에서는 여러 채널에서 이 모든 데이터를 수집하고 분석해야 합니다. 따라서, 데이터를 서비스나 부가가치용 비즈니스 자산으로 제공하려는 기업이 비즈니스 파트너사에게 데이터에 대해 쉽고 빠른 접근을 제공하기 위해 노력하는 것은 굉장히 자연스러운 현상입니다.
5.4. 데이터 상용화 기회 증가
최신 클라우드 데이터 공유는 온-프레미스와 클라우드에 배포 운영되는 전통적인 DW의 기존 데이터 공유 장벽을 제거함으로써, 기업이 데이터를 수익화를 위한 자산으로 빠르고, 쉽고, 안전하게 공유할 수 있게 함으로써 진정한 데이터 경제를 지원하는 다음 4가지 새로운 비즈니스 측면의 기회를 제공합니다:
» 데이터 수익화(Data monetization): 오늘날 일부 기업들은 데이터를 생산하고 판매하고 있습니다. 이제 최신 데이터 공유를 통해 모든 기업들은 자사 DW에 저장된 데이터를 대상으로 데이터의 규모와 관련 없이 일부 또는 전체를 공유하고 데이터 사용에 대한 과금을 청구함으로써 새로운 비즈니스 수익 모델로 전환할 수 있습니다. 이와 같은 해법을 통해 데이터 기반의 기업들은 데이터 소비자의 요구에 대해 최상의 데이터 품질을 기반으로 바로 제공함으로써 소비자의 요구사항을 충족할 수 있습니다.
» 비즈니스 파트너와의 데이터 공유(Data sharing with business partners): 비즈니스 파트너와 직접 데이터를 공유하는 것은 사실 새로운 것이 아니지만, 라이브 데이터를 손쉽게 공유할 수 있다는 것은 굉장히 획기적입니다. 최신 클라우드 데이터 공유는 다음을 가능하게 합니다:
- 기업이 비즈니스 에코시스템의 일부인 다른 기업과 데이터를 즉시 공유 - 예: 공급망, 유통, 마케팅, 3rd 판매를 포함
- 어떤 기업이 데이터를 소유하고 또는 데이터 공급자와 소비자의 역할을 수행하는 것과 관련없이, 데이터 소비자가 라이브 데이터를 즉시 사용할 수 있다는 것은 데이터 공급자와 소비자 모두에게 상호 이익을 제공하는 것입니다.
- 시스템의 과부하 없이 기존 데이터 공유 방식보다 휠씬 저렴한 비용으로 내/외부 데이터를 활용하여 분석을 수행함으로써 데이터 기반의 비즈니스 결정을 더 빠르게 가속화 할 수 있습니다.
» 기업 내의 사일로 된 분석 환경 제거: 최신 데이터 공유는 정형 및 반정형 데이터를 현대화된 클라우드 DW에 쉽게 저장하고 활용할 수 있게 함으로써, 기업 내에 존재하는 사일로 된 데이터 분석 환경을 제거합니다. 데이터는 다운로드나 복제 없이 원활하게 공유할 수 있습니다. 이전에 사일로된 시스템에서 요구된 별도의 데이터 파이프라인을 포함한 동기화 작업 없이 긴밀하고, 간편하게 통합될 수 있습니다.
» 더 많은 데이터 소비자를 수용하기 위한 제로 관리(Zero management): 현대화된 DW는 하드웨어 조정, 시스템 튜닝이 불필요한 성능을 제공하기 때문에, 현대화된 클라우드 DW만이 레거시 DW를 관리하는 데 요구된 시간-소모적인 방법을 제거합니다. 관리가 불필요하기 때문에, 기업은 기업 내/외부와 함께 더 많은 데이터 소비자 기반을 대상으로 하는 데이터 공유 전략을 수립하고 실행할 수 있습니다.
데이터 공유는 기술적인 가능성과 비즈니스 모델로서만 존재하기 때문에, 단순하게 셀프-서비스 환경을 쉽게 구축할 수 있다는 것을 의미합니다. 데이터 공급자와 소비자 간의 데이터 공유에 대한 비즈니스 약정은 사용자의 몫입니다.
6. 최신 방식의 데이터 공유로 비즈니스를 진화하는 6단계
지금까지 최신 데이터 공유의 엄청난 잠재력과 기존 데이터 공유 방식의 문제점을 알아봤습니다. 이제부터 최신 데이터 공유를 기업 환경에 도입, 적용하는 6가지 주요 단계를 간략하게 살펴보도록 하겠습니다:
1. 데이터 공유의 장벽과 기회를 발견: 이 단계의 목표는 조직 내의 데이터 공유의 현재와 예측 가능한 가까운 시일의 요구사항을 수집하는 것입니다. 데이터를 공유하기 위해서는 현재 구축되어 운영 중인 데이터 공유 프로세스와 데이터 플루우가 사전에 마련되어 있어야 합니다. 만일 이에 관련된 정보가 있는 경우, 가장 효과적인 가치를 창출 할 수 있는 데이터를 식별하는 데 집중해야 합니다. 궁극적인 목표는 IT, DW 및 현업 분석 부서에서 데이터를 분석하는 데 걸림돌이 되는 데이터 공유와 전송 프로세스를 식별하는 것입니다. 이러한 기술적, 오퍼레이션적 장벽으로 인해 데이터에서 새로운 비즈니스 가치를 창출하는 데 지연이 발생합니다. 관련된 지연 요소를 파악한 뒤, 데이터 공유 비즈니스 계획을 더 쉽고 빠르게 실행 할 수 있는 단계를 설정해야 합니다. 이 단계에서 파악해야 하는 정보는 다음과 같습니다:
- 데이터: DW에는 어느 유형의 데이터가 포함되어야 하며, 새로운 데이터가 생성되는 속도는 어떠한가요? 데이터 수집에 관련된 배치 작업은 얼마나 되나요?
- 데이터 흐름(Data Flow): 현재 구축 운영 중인 DW에서 다른 부서의 시스템과의 데이터 연계 흐름을 식별해야 하며, 데이터 공유를 요구하는 부서 또는 조직의 수를 파악해야 합니다. 또한, 데이터 연계가 기업 내/외부인지를 식별해야 합니다.
- 작업 프로세스(Work process): 어느 부서가 데이터 공유 및 데이터 전송에 대한 프로세스를 관리/운영하고 있나요? 데이터 공유, ETL, 동기화를 위해 사용되는 도구는 무엇인가요? 데이터 수집 및 처리를 담당하는 부서와 논의하여 데이터 공유 시 직면한 어려움을 파악해야 합니다.
- 미래의 time-to-market & time-to-insight 목표 설정: 현재 사용하는 도구 및 데이터 공유를 위해 알고 있는 경험을 고려하지 않고, 비즈니스적인 측면에서 현재 및 근시일에 데이터 공유 요구사항을 파악해야 합니다. 이 정보를 기반으로 현재 처리 방식으로 데이터 공유에 대해 너무 많은 지연 시간이 발생하는 것과 이 문제를 해결함으로써 얻을 수 있는 비즈니스 가치를 강조하고 설명해야 합니다.
2. 개별 사용 사례에 대한 역할을 정의: 기업의 이니셔티브를 새로운 수준으로 끌어올리려면, 비전과 목표를 수립하고 실현할 수 있는 챔피언이 필요합니다. 특히, 부서 단위의 IT 및 DW 영역의 부분적인 개선으로 원하는 목표를 달성할 수 없습니다. 이를 위해 필요한 것은:
- 현재와 미래의 데이터 공유 사용이 필요한 사례를 식별해야 합니다.
- 데이터 공유에 참여해야 하는 내/외부 부서 및 회사를 식별해야 합니다. 모든 데이터 공유 관계에는 데이터 공급자와 소비자의 개별적인 이해관계가 존재하기 때문에, 조직별 개별 사용 사례에 대해 데이터 공유의 역할을 명확하게 정의해야 합니다. 데이터 공유에 대한 조직 구조를 가급적 단순하게 유지하도록 노력해야 합니다.
- 데이터 공급자 역할에 대해 - 데이터 소비자를 식별하고 데이터 공유에 참여 시켜 최신 데이터 공유 전략을 채택하도록 유도해야 합니다.
- 데이터 소비자 역할에 대해 - 데이터 공급자에게 최신 데이터 공유 접근법에 대한 이점을 설명하여 동일한 데이터 공유 전략을 채택하도록 유도해야 합니다.
3. 현재 구축된 DW의 데이터 공유 기능 확인: 현재 사용 중인 DW가 최신 데이터 공유 기능을 쉽게 구현이 가능하며 비용-효율적으로 지원할 수 있는지 확인해야 합니다. 최신 데이터 공유 기능을 제공하는지 확인하기 위해서는 다음과 같은 기능이 지원되는지를 파악해야 합니다.
- 데이터 이동 불필요: 최신 데이터 공유는 데이터나 파일의 이동, ETL 작업 없이 데이터를 공유하는 것을 의미합니다. 이는 데이터 공유를 위한 번거롭고 부담이 되는 작업이기 때문에, 데이터 이동에 관련된 작업을 제거하면, 데이터 공유를 위한 더 좋은 방법을 찾을 수 있습니다.
- 실시간 변경 데이터 동기화: 데이터 제공자로서 라이브 한 데이터를 활용함으로써 데이터의 가치는 높아집니다. 최신의 데이터일수록 데이터 소비자는 공유된 데이터로부터 더 많은 가치를 창출하여 새로운 수익을 얻을 수 있다고 인식합니다. 대부분의 데이터 소비자는 항상 최신의 데이터를 기반으로 분석 업무를 수행하기를 원합니다.
- 개인화된 보안 뷰(Secure View): 최신 데이터 공유는 데이터 소비자에게 DW에 보유하고 있는 모든 데이터-셋에 대한 접근을 허용하는 것을 의미하지 않습니다. 개별 데이터 소비자들이 요구하는 필요한 데이터 뷰를 쉽게 제공할 수 있는 세분화된 제어 기능이 필요합니다. 최신 데이터 공유는 1:1, 1:n 및 n:n과 같은 유연한 데이터 공유 관계를 지원합니다.
- 데이터 무결성을 보증하는 단일 데이터 소스: 데이터 공급자가 데이터를 갱신할 때마다, 현대화된 DW는 데이터 소비자에게 변경 사항이 반영된 최신의 데이터를 제공합니다. 이는 데이터 제공자 또는 소비자에서 별도의 작업이 없어야 가능합니다. 데이터 소비자는 데이터 가치를 극대화하기 위해 여기서 언급한 수준의 데이터 무결성을 원합니다.
4. PoC 수행: 앞서 살펴본 데이터 공유의 기능을 제공하는 솔루션 업체를 검토한 뒤, 가능한 빨리 PoC를 수행해야 합니다. PoC를 통해 현재 기업에서 요구하는 데이터 공유 요구 사항과 성공 기준을 얼마나 잘 충족하는지 확인하는 단계입니다. PoC 결과를 통해 현재 운영중인 DW의 접근 방식과 최신 데이터 공유의 특/장점을 비교 분석해야 합니다. PoC 검증 시나리오로 현재 DW에서 실행되는 작업 외에 다른 시나리오를 고려해야 합니다. 만일 최신 데이터 공유 기능을 제공하는 클라우드-기반의 DW를 사용하고 있다면, 이 시스템에서 제공할 수 있는 추가적인 비즈니스 가치가 무엇인가요? DW에 보유한 일부 데이터를 활용하여 데이터 수익화를 달성할 수 있나요? PoC 시나리오에는 현재 및 미래의 데이터 공유에 관련된 모든 요구 사항과 성공 기준이 반영되어야 합니다. 예를 들어, 현재 운영 중인 DW에 운영상 경험한 불만 및 개선사항이나, 장시간 소요되는 쿼리가 있다면 이 문제에 대해서만 검증을 해서는 안 됩니다. PoC는 데이터를 새로운 솔루션으로 쉽게 마이그레이션하고, 새로운 정형 및 반정형 데이터를 로드하고, 쿼리를 수행하고, 여러 워크로드 수용 여부를 포함하여 모든 요구 사항이 포함되어 검증되어야 합니다.
5. 지원 계획을 수립: 데이터 소비자를 참여시키는 데 필요한 단계를 간략하게 설명해야 합니다. 최신 데이터 공유는 다양한 데이터 공유 관계를 지원하기 때문에, 데이터의 가치와 데이터 소비자가 이로부터 얻을 수 있는 이점을 명확하게 공유해야 합니다.
6. 실행: 비즈니스 이해 관계자에게 Time-To-Market 및 Time-To-Value를 개선할 수 있는 것을 보여 주워야 합니다. PoC 완료 후, 데이터 공유에 관련된 모든 이해 관계자들에게 최신 데이터 공유의 이점을 시연을 통해 직접 확인시켜야 합니다. 또한, 데이터 공급자와 소비자 입장에서 데이터 공유를 위해 소요되는 시간 및 비용 절감을 추정하고, 기업에서 얻을 수 있는 생산성 향상 및 데이터를 통해 얻을 수 있는 새로운 수익 창출 잠재력을 예측합니다. 최종 목표는 최신 데이터 공유 및 클라우드-기반의 DW에 대한 ROI 추정치를 도출하는 것이며, 이는 기업이 새로운 차원의 기능과 기회로 최신 데이터 공유를 성공적으로 수행할 수 있는 원동력이 됩니다.
'Snowflake - The Data Cloud' 카테고리의 다른 글
| Snowflake Data Cloud (0) | 2021.12.08 |
|---|---|
| Cloud Data Platforms (0) | 2021.12.08 |
| Cloud Data Lakes (0) | 2021.12.07 |
| Snowflake – Partitioning (0) | 2021.11.30 |
| Snowflake Elastic Data Warehouse (0) | 2021.11.21 |



