Part I : Performance of MIN/MAX Functions - Metadata Operations & Partition Pruning
Snowflake는 테이블 데이터를 마이크로 파티셔닝 기반으로 저장하며, 모든 파티션의 개별 데이터와 전체 테이블에 대한 MIN/MAX 통계 값은 Snowflake 내부 테이블 형태로 저장보관됩니다. 우선은 MIN/MAX 통계값을 활용하여 SQL 쿼리 성능에 어떤 영향을 미치는지 살펴보도록 하겠습니다. 예를 들어 625억 건의 데이터 레코드가 있는 9.1TB 데이터-셋이 있는 이벤트 테이블이 있다고 가정해 보겠습니다. 최초 쿼리는 매우 간단합니다:
SELECT MIN(event_hour), MAX(event_hour)
FROM events;
--------------
0 23
쿼리가 완료되는데는 단 408ms만이 소요되었습니다. Snowflake의 쿼리 실행 프로파일을 보면 메타정보에 관련된 오퍼레이션(METADATA-BASED RESULT)만을 수행하였으며, 쿼리 수행을 위해 스캔된 데이터가 없음을 알 수 있습니다, 즉 Snowflake 내부에 관리되는 통계 정보를 활용하기 때문에 실제 데이터 기반의 상호작용은 필요없습니다:
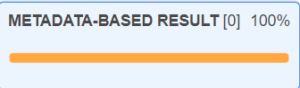
이제 필터를 추가해 보도록 하겠습니다:
SELECT MIN(event_hour), MAX(event_hour)
FROM events
WHERE event_date = '2019-04-30';
이 쿼리를 실행하는 데는 5초가 소요되었습니다. Snowflake는 전체 테이블 및 마이크로 파티션기반으로 데이터를 수집했기 때문에 해당 쿼리에 대해 event_hour 컬럼에 대한 MIN/MAX 통계 정보를 활용할 수 없지만, 지정된 날짜 내의 MIN/MAX 값을 사용하는 것을 알 수 있습니다. 즉, 해당 쿼리는 역시 빠르게 처리되었습니다:
Bytes scanned 376.53 MB
Partitions scanned 2,092
Partitions total 828,926
Snowflake는 테이블의 828,926 개의 파티션 중 2,092개의 파일을 대상으로만 읽기 작업을 수행한 것을 알 수 있습니다. 이는 이벤트 테이블의 event_date 컬럼에 대해서 잘 정렬(클러스터링)되어 있음을 의미합니다. 즉, 대부분의 마이크로 파티션은 파티션을 구성하는 모든 컬럼인 event_date의 상수 값을 가지므로, Snowflake는 파티션 수준에서 MIN/MAX 통계 정보를 효율적으로 적용하고 지정된 날짜가 포함되지 않은 파티션의 데이터 파일은 데이터 스캔 작업의 대상에서 제외함을 의미합니다.
이제 다른 필터를 적용해 보도록 하겠습니다:
SELECT MIN(event_hour), MAX(event_hour)
FROM events
WHERE event_name = 'LOGIN';
해당 쿼리가 실행되는데는 7분 48초가 소요되었습니다. Snowflake는 이전 쿼리와 비교했을 때 더 많은 데이터를 스캔해야 했습니다:
Bytes scanned 121.7 GB
Partitions scanned 769,848
Partitions total 828,926
Snowflake는 해당 테이블의 거의 모든 파티션에 저장된 데이터 파일을 스캔 처리했습니다. 이전 쿼리 예에서는 테이블이 event_date 컬럼에 대해서 잘 클러스터링 되어 있는것을 확인할 수 있었지만, event_name 필터의 동작에 대해서는 다음 두 가지를 생각해 볼 수 있습니다:
1. 본 예와 같이 테이블의 데이터는 event_name 컬럼에 관해서는 비 효율적으로 클러스터링되어 있을 수 있습니다. 예를 들어 상대적으로 적은 수의 LOGIN 데이터가 존재할 수 있지만, event_name 컬럼의 값이 "LOGIN"이라는 데이터는 모든 파티션 데이터 파일에 분산되어 저장되었기 때문에, 쿼리 수행 시점에 evet_date 컬럼을 대상으로 필터링한 결과와 다르게 대다수의 파일들을 스킵처리 할 수 없습니다.
즉, 동일한 이벤트 데이터를 동일한 파티션으로 이동하는 테이블을 다시 클러스터링하면, event_name 필터가 적용될 때 Snowflake는 해당 테이블을 더 효율적으로 쿼리하고 더 많은 파티션 파일들을 대상으로 pruning 처리 할 수 있습니다.
2. 다른 관점은 너무 많은 LOGIN 데이터가 존재할 수 있습니다. 많은 데이터 레코드가 모든 파티션에 존재함을 의미합니다. 즉, 이 데이터로 인해 테이블 데이터는 불균형하게 저장되고 모든 데이터의 80~90%가 이와 관련된 데이터 일 수 있습니다. 이 경우, Snowflake는 파티션 기반으로 데이터 읽기 작업을 수행하기 때문에 re-clustering은 도움이 되지 않습니다. 그러나 클러스터링은 데이터 스큐가 발생하지 않는 다른 값으로 더 효율적으로 필터링하는 데 도움이 될 수 있습니다.
최악의 시나리오인 "LOGIN"이라는 데이터가 event_name 컬럼에 많이 저장되어 있다고 가정하더라도, Snowflake는 컬럼형 스토리지를 사용하여 두 개의 컬럼에 대해서만 스캔 작업을 처리하기 때문에 전체 테이블의 크기의 1.3%(121.7GB)만을 대상으로 읽기 작업을 수행한 것을 알 수 있습니다. 즉, 전체 데이터인 9.1TB를 읽을 필요가 없기 때문에 굉장히 효율적인 방법입니다.
Part II : Micro-Partitions & Clustering
전통적인 DW에서는 PARTITIONED BY 절을 사용하여 테이블에 대한 파티션 컬럼을 명시적으로 지정해야 합니다. 하지만, Snowflake는 내부적으로 파티션 기법을 활용하지만 테이블을 생성할 때 PARTITIONED BY 절을 정의할 필요가 없습니다.
Partitioning
DW 시스템은 대용량 데이터를 저장하며, 때때로 히스토리 데이터를 수 년 동안 보관하고 있으며, 동시에 데이터 분석가는 모든 데이터를 대상으로 쿼리를 수행하지 않습니다. 대부분의 경우, 최근 몇 일, 몇 주 또는 특정 기간 동안의 데이터에 대해서만 관심을 가지고 있습니다.
테이블 파티셔닝, 즉 대용량 테이블에 대해서 event_date 또는 order_date와 같은 컬럼을 기반으로 여러 개의 작은 부분으로 분활하는 것은 매우 편리하고 실용적인 방법입니다. 예를 들이, 다음 쿼리에서는 전체 테이블의 데이터가 아닌 단 5일 동안의 데이터 만을 필요로 합니다:
SELECT city, product, COUNT(*)
FROM events
WHERE event_date BETWEEN '2019-11-25' AND '2019-11-29'
and event_type = 'LOGIN'
GROUP BY city, product
이러한 최적화는 Partition Pruning이라고 합니다. 일일 데이터는 매우 크고 수백만개의 데이터가 포함될 수 있기 때문에 파티셔닝은 OLTP 데이터베이스에서 사용되는 인덱스보다 더 효율적인 방식입니다.
Micro-Partitions
Snowflake에서는 사용자가 명시적으로 파티션을 정의하지 않더라도 모든 데이터는 마이크로-파티션(micro-partition)이라는 Snowflake 내부 파티션에 자동으로 저장됩니다.
개별 마이크로-파티션은 컬럼형으로 구조화된 50~500MB의 압축되지 않은 데이터(실제로는 압축되어 저장됨)가 포함되며, 각 마이크로 파티션에 대해 Snowflake는 쿼리 시점에 파티션 프루닝(partition pruning)에 도움이 되는 개별 컬럼의 통계 정보를 저장합니다.
파티션의 수가 상대적으로 적은 기존 DW의 테이블과 달리(예: 하루 및 제품당 파티션 1개), Snowflake의 테이블은 수백만개의 파티션을 쉽게 생성되어 사용될 수 있습니다.
Clustering
새로운 데이터가 지속적으로 수집되면, 마이크로 파티션에 로드되는 일부 컬럼(예: event_date)는 모든 파티션에서 상수 값(자동으로 클러스터링)을 갖는 반면 다른 컬럼(예: city)는 모든 파티션에서 동일한 값을 계속해서 나타날 수 있습니다:

다음 쿼리를 수행하면, :
SELECT product, COUNT(*)
FROM events
WHERE event_date = '2019-11-28'
GROUP BY product
Snowflake는 파티션 P1, P2 및 P3에 저장된 데이터 파일을 대상으로만 데이터 읽기 작업을 수행합니다. 하지만, 다른 쿼리를 살펴보면:
SELECT product, COUNT(*)
FROM events
WHERE city = 'Amsterdam'
GROUP BY product
city 컬럼에 대해서만 필터링을 적용했지만, Snowflake는 데이터가 거의 모든 파티션에 분산되어 있기 때문에, P5를 제외한 모든 파티션에서 데이터를 읽어야 합니다:
다음 쿼리를 살펴보면:
SELECT product, COUNT(*)
FROM events
WHERE city = 'Dublin'
GROUP BY product
Snowflake는 P5 및 P6 파티션에 대해서만 데이터를 읽습니다. Snowflake는 파티션에 대한 MIN/MAX 컬럼 통계 정보를 저장하여 활용하기 때문에, "Dublin" 값이 MIN(Amsterdam)과 MAX(Florence) 내에 존재하기 때문에 P6의 파티션도 데이터 스캔의 대상이 됩니다.
따라서, 해당 테이블은 City 컬럼에 대해서 클러스터링이 잘되어 있지 않았기 때문에 클러스터링에 대한 이점을 얻을 수 있다고 말할 수 없습니다. Snowflake는 데이터 분배를 위해 하나 이상의 컬럼들을 클러스터링 키로 정의 할 수 있습니다. 예를 들어, :

이제 City 열에 대한 필터가 있는 쿼리는 휠씬 적은 데이터를 대상으로 스캔 작업을 수행합니다:
Constant Partitions
테이블은 데이터 패턴이 일관되지 않기 때문에 클러스터링에 대해 어떤 컬럼을 사용하는 경우 잘 분산되어 저장될 수도 있지만, 다른 컬럼을 사용하는 경우 그렇지 못할 수도 있습니다.
Snowflake에서는 상수 파티션이라는 용어에도 이 개념이 동일하게 적용됩니다. 파티션의 모든 데이터가 동일 컬럼에 대한 같은 단일 값을 갖는 경우, 파티션은 해당 컬럼에 대해 일정합니다:

왜 이 부분이 중요할 까요? 테이블의 모든 파티션이 일정하다면, 이 컬럼에 대한 필터가 적용된 쿼리는 조건을 충족하는 파티션의 데이터를 대상으로 스캔 작업을 수행하며, 다른 파티션에 대해서는 스킵 처리를 할 수 있습니다. 즉, 필터링은 단순한 메타데이터 오퍼레이션입니다.
위의 그림에서, 모든 파티션이 일정하고 type='A' 필터가 적용된 쿼리는 'A' 값을 보유하고 있는 파티션 P1과 P3를 대상으로만 데이터 스캔 작업을 수행합니다.
파티션 중복(Partition Overlaps)
파티션의 값이 상수가 아니더라도 다음과 같이 데이터의 값은 중복 저장되지 않을 수도 있습니다:

위 그림에서 "type='A'" 필터를 가진 쿼리는 파티션 P1과 P4만을 읽지만 이 파티션에 저장된 값 'B'를 가진 행을 읽고 쿼리 대상에서 제거해야 합니다. 다른 예를 생각해 보도록 하겠습니다. 이제 모든 파티션의 값이 겹쳐 있습니다:

비록 5개이 모든 파티션이 중첩되어 있지만 "type='B'" 필터를 가진 쿼리는 P1 및 P2 파티션의 데이터만 읽으면됩니다. 이제 값 A와 C를 스캔한 뒤 쿼리 대상에서 제외해야 합니다.
Clustering Depth
다음 한 가지 예를 더 고려해보면:

5개의 모든 파티션의 데이터가 중첩 저장되어 있지만, "type='B'" 필터가 적용된 쿼리는 모든 파티션의 파일들을 모두 스캔처리해야 합니다. 따라서 파티션의 중첩 횟수는 마지막 2개의 예와 동일하지만 클러스터 깊이가 다릅니다. 테이블에 중첩된 모든 마이크로 파티션과 특정 컬럼의 MIN/MAX 값을 활용하면, 해당 컬럼에 대한 클러스터링 깊이를 계산할 수 있습니다.

쿼리의 필터가 중첩된 마이크로 파티션이 경우 클러스터링 깊이는 해당 컬럼을 대상으로 적용된 필커를 가진 쿼리가 얼마나 많은 파티션을 평균적으로 읽어야 하는지을 알려줍니다.
Snowflake는 테이블과 특정 컬럼에 대한 클러스터링 정보를 계산하는 기능을 제공합니다:
SELECT system$clustering_information('events', '(event_date)')
event_date 컬럼에 대한 샘플 결과:
{
"cluster_by_keys" : "LINEAR(EVENT_DATE)",
"total_partition_count" : 2672931,
"total_constant_partition_count" : 2598036,
"average_overlaps" : 40538.536,
"average_depth" : 31064.0861,
"partition_depth_histogram" : {
"00000" : 0,
"00001" : 2598003,
"00002" : 0,
"00003" : 0,
"00004" : 3,
"00005" : 0,
...
"00015" : 0,
"00016" : 0,
"00512" : 1,
"02048" : 4423,
"04096" : 11403,
"08192" : 3896,
"32768" : 7955,
"65536" : 47247
}
}
여기에서 대부분의 파티션이 event_date 컬럼에 대해 일정(250만 또는 97%)합니다. 클러스터링 깊이가 32,768에서 65,535 사이인 파티션이 47,247개 있습니다. 이제 city 컬럼을 확인해 보도록 하겠습니다:
SELECT system$clustering_information('events', '(city)')
위 쿼리 결과는 다음과 같습니다:
{
"cluster_by_keys" : "LINEAR(CITY)",
"total_partition_count" : 2673936,
"total_constant_partition_count" : 0,
"average_overlaps" : 2673935.0,
"average_depth" : 2673936.0,
"partition_depth_histogram" : {
"00000" : 0,
"00001" : 0,
"00002" : 0,
"00003" : 0,
"00004" : 0,
"00005" : 0,
...
"00016" : 0,
"4194304" : 2673936
}
}
파이션도 일정하지 않고 클러스터링 깊이는 테이블의 파티션 수와 같습니다. 즉, 도시 컬럼 필터가 있는 쿼리는 항상 260만 개의 파티션이 있는 전체 테이블을 읽습니다.
결론
- 클러스터링은 사용자 쿼리 성능을 개선할 수 있지만, 특정 컬럼에 대한 정의가 필요하기 때문에 쿼리 사용 패턴을 분석해야 합니다. 즉, 클러스터링을 정의한 컬럼에 대해서는 잘 정렬되어 쿼리 성능을 최적화 할 수 있지만, 다른 쿼리에 대해서는 정렬이 되어 있지 않기 때문에 원하는 성능을 얻을 수 없습니다 .
- 파티션 중첩은 클러스터링 깊이보다 덜 중요하지만 클러스터링 깊이가 일정하지않은 파티션에 대해서만 계산되므로 테이블의 모든 파티션 중 해당 비율을 알아야 합니다.
'Snowflake - The Data Cloud' 카테고리의 다른 글
| Snowflake Data Cloud (0) | 2021.12.08 |
|---|---|
| Cloud Data Platforms (0) | 2021.12.08 |
| Cloud Data Lakes (0) | 2021.12.07 |
| Snowflake Elastic Data Warehouse (0) | 2021.11.21 |
| Snowflake의 데이터 공유(Data Sharing) (0) | 2021.11.20 |



